
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Data Science
- Robocup@Home 2026
- CPP
- C++
- Machine Learning
- DFS
- Optimization
- Linux
- Multimedia
- do it! 알고리즘 코딩테스트: c++편
- Python
- Operating System
- ROS2
- RNN
- System Call
- CNN
- paper review
- Seoul National University
- deep learning
- Baekjoon
- computer vision
- BFS
- On-memory file system
- 밑바닥부터 시작하는 딥러닝2
- SQLD
- Gentoo2
- Humble
- file system
- Process
- cs231n
- Today
- Total
newhaneul
[Advanced Python Programming] Lecture 11. Numpy 본문
[Advanced Python Programming] Lecture 11. Numpy
뉴하늘 2026. 4. 17. 16:15포스팅은 인하대학교 허혜선 교수님의 [202601-EEC3408-001] 고급파이썬프로그래밍을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
1. Numpy
- 벡터화(Vectorization) 연산: 원소끼리의 연산이 이루어지는 것
- 브로드캐스팅(Broadcasting): 모든 원소에 대해 같은 연산을 적용하는 것


import numpy as np
a = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
b = np.array((0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
c = np.array(range(0, 10))
print(a)
print(b)
print(c)
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]import numpy as np
b = np.array(range(0, 10, 2))
print(b)
[0 2 4 6 8]
- np.array(리스트): 1차원 ndarray 배열 생성
- .max(): 최대 값을 반환
- .min(): 최소 값을 반환
- .mean(): 평균 값을 반환
- .flatten(): ndarray 배열을 1차원 배열로 평탄화
- np.append()
import numpy as np
a = np.array([1, 2, 3])
b = np.array([[4, 5, 6], [7, 8, 9]])
c = np.append(a, b)
print(c)
d = np.append([a], b, axis = 0)
print(d)
[1 2 3 4 5 6 7 8 9]
[[1 2 3]
[4 5 6]
[7 8 9]]
- np.random.rand(a, b): (a, b) shape의 난수 생성
import numpy as np
a = np.random.randn(3, 3)
print(a)
[[-0.13769801 1.48710473 -1.09145119]
[ 0.3524087 0.17045809 0.79123598]
[-0.48311612 -0.12871156 0.00689848]]
- np.random.randint(a, b, size = c): a에서 b 사이의 c개의 난수 생성
import numpy as np
a = np.random.randint(0, 10, size = 10)
print(a)
[6 8 5 5 1 9 2 9 6 1]


import numpy as np
a = np.array([23, 45, 67, 7, 2, 30, 34, 82])
print(f"최댓값: {a.max()}")
print(f"최솟값: {a.min()}")
print(f"평균: {a.mean()}")
최댓값: 82
최솟값: 2
평균: 36.25import numpy as np
b = np.random.randint(0, 100, size = 10)
print(f"b = {b}")
print(f"최댓값: {b.max()}")
print(f"최솟값: {b.min()}")
print(f"평균: {b.mean()}")import numpy as np
a = np.array([23, 45, 67, 7, 2, 30, 34, 82])
b = np.random.randint(0, 100, size = 10)
c = np.append(a, b)
print(c)
[23 45 67 7 2 30 34 82 61 96 62 66 88 49 39 83 93 11]
- 행렬 곱 연산
- np.matmul(a, b)
- np.dot(a, b)
- a @ b

import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = np.array([[2, 2, 2], [2, 2, 2], [2, 2, 2]])
print(a+b) # [[3 4 5] [6 7 8] [9 10 11]]
print(a-b) # [[-1 0 1] [2 3 4] [5 46 7]]
print(a*b) # [[2 4 6] [8 10 12] [1 16 18]]
print(a/b) # [[0.5 1 1.5] [2 2.5 3] [3.5 4 4.5]]
print(a@b) # [[12 12 12] [30 30 30] [48 48 48]]
print(a**2) # [[1 4 9] [16 25 36] [49 64 81]]
[[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[-1 0 1]
[ 2 3 4]
[ 5 6 7]]
[[ 2 4 6]
[ 8 10 12]
[14 16 18]]
[[0.5 1. 1.5]
[2. 2.5 3. ]
[3.5 4. 4.5]]
[[12 12 12]
[30 30 30]
[48 48 48]]
[[ 1 4 9]
[16 25 36]
[49 64 81]]
- np.zeros((n, m)): 모든 값이 0인 n x m 행렬
- np.ones((n, m)): 모든 값이 1인 n x m 행렬
- np.full((n, m), x): 초기 값이 x인 n x m 행렬
- np.eye(n): n x n 크기의 단위 행렬
import numpy as np
a = np.zeros((2, 3))
b = np.ones((2, 3))
c = np.full((2, 3), 100)
d = np.eye(2)
print(a)
print(b)
print(c)
print(d)
[[0. 0. 0.]
[0. 0. 0.]]
[[1. 1. 1.]
[1. 1. 1.]]
[[100 100 100]
[100 100 100]]
[[1. 0.]
[0. 1.]]
- np.linspace(start, stop, num): start에서 stop 사이의 간격을 균등하게 num으로 나눈다.
- np.logspace(start, stop, num): start에서 stop 사이의 간격을 로그 스케일로 num 개 만큼 나누어 생성한다.

import numpy as np
a1 = np.full((3, 3), 2)
a2 = np.arange(1, 13)
a3 = np.arange(0, 50, 3)
a4 = np.linspace(0, 20, 5)
print(a1)
print(a2)
print(a3)
print(a4)
[[2 2 2]
[2 2 2]
[2 2 2]]
[ 1 2 3 4 5 6 7 8 9 10 11 12]
[ 0 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45 48]
[ 0. 5. 10. 15. 20.]
- np.arange(0, 10): 0에서 9까지의 1차원 행렬 생성
- np.arange(0, 10).reshape(2, 5): 0에서 9까지의 원소 값을 가지며, shape이 (2, 5)인 행렬 생성


import numpy as np
a1 = np.arange(1, 13).reshape(2, 6)
a2 = np.arange(1, 31).reshape(3, 10)
print(a1)
print(a2)
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]]
[[ 1 2 3 4 5 6 7 8 9 10]
[11 12 13 14 15 16 17 18 19 20]
[21 22 23 24 25 26 27 28 29 30]]import numpy as np
a2 = np.arange(1, 31).reshape(3, 10)
a3 = a2.reshape(6, 5)
a4 = a3.transpose()
print(a2)
print(a3)
print(a4)
[[ 1 2 3 4 5 6 7 8 9 10]
[11 12 13 14 15 16 17 18 19 20]
[21 22 23 24 25 26 27 28 29 30]]
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]
[21 22 23 24 25]
[26 27 28 29 30]]
[[ 1 6 11 16 21 26]
[ 2 7 12 17 22 27]
[ 3 8 13 18 23 28]
[ 4 9 14 19 24 29]
[ 5 10 15 20 25 30]]
2. Numpy axis
- 2차원 배열에서 axis 0은 행의 방향이며, axis 1은 열의 방향을 의미한다.

- np.insert(arr, obj, values, axis=None)
- arr: 값을 추가할 원본 배열
- obj: 값이 삽입될 기준 인덱스
- values: 추가할 값
- axis: 값을 추가할 축(방향)
- axis = 0: 행(Row) 단위로 삽입
- axis = 1: 열(Column) 단위로 삽입
import numpy as np
a = np.array([1, 3, 4])
print(np.insert(a, 1, 2))
b = np.array([[1, 1], [2, 2], [3, 3]])
print(np.insert(b, 1, 4, axis=0))
print(np.insert(b, 1, 4, axis=1))
[1 2 3 4]
[[1 1]
[4 4]
[2 2]
[3 3]]
[[1 4 1]
[2 4 2]
[3 4 3]]

import numpy as np
a = np.random.randint(1, 101, size=15).reshape(3, 5)
print(a)
print(f"a의 열방향 최댓값: {a.max(axis=0)}")
print(f"a의 열방향 최솟값: {a.min(axis=0)}")
print(f"a의 열방향 평균: {a.mean(axis=0)}")
print(f"a의 행방향 최댓값: {a.max(axis=1)}")
print(f"a의 행방향 최솟값: {a.min(axis=1)}")
print(f"a의 행방향 평균: {a.mean(axis=1)}")
[[23 31 14 69 47]
[70 82 75 13 57]
[27 39 64 81 33]]
a의 열방향 최댓값: [70 82 75 81 57]
a의 열방향 최솟값: [23 31 14 13 33]
a의 열방향 평균: [40. 50.66666667 51. 54.33333333 45.66666667]
a의 행방향 최댓값: [69 82 81]
a의 행방향 최솟값: [14 13 27]
a의 행방향 평균: [36.8 59.4 48.8]
3. Numpy Indexing, Slicing
import numpy as np
a = np.arange(1, 11)
b = a[[1, 3, 5, 7]]
print(b)
[2 4 6 8]import numpy as np
a = np.arange(1, 11)
print(a[5:])
print(a[6:])
print(a[:3])
print(a[::2])
print(a[::-2])
[ 6 7 8 9 10]
[ 7 8 9 10]
[1 2 3]
[1 3 5 7 9]
[10 8 6 4 2]


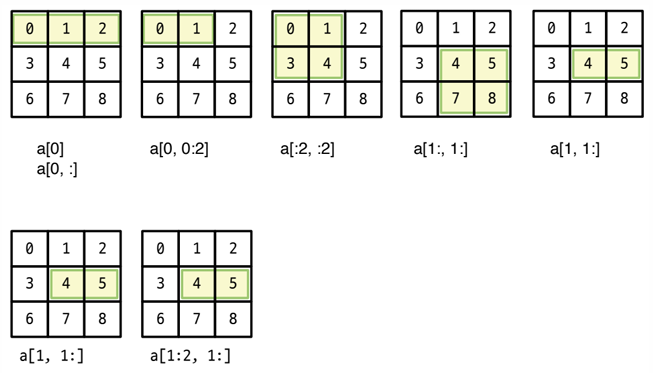

import numpy as np
a = np.arange(0, 16).reshape(4, 4)
print(a[:, 1])
print(a[2, 1:])
print(a[:2, :2])
print(a[1:3, 1:3])
[ 1 5 9 13]
[ 9 10 11]
[[0 1]
[4 5]]
[[ 5 6]
[ 9 10]]import numpy as np
a = np.arange(0, 16).reshape(4, 4)
print(a[:2, :3].flatten())
print(a[2:, :].flatten())
print(a[[1, 3], 1:].flatten())
[0 1 2 4 5 6]
[ 8 9 10 11 12 13 14 15]
[ 5 6 7 13 14 15]
4. 선형 방정식 풀이
- np.linalg.solve(a, b)
- np.linalg.det(A)

import numpy as np
a = np.array([[1, 1, -1], [2, -1, 3], [1, 2, 1]])
b = np.array([0, 9, 8])
c = np.linalg.solve(a, b)
print(f"x = {c[0]}, y = {c[1]}, z = {c[2]}")
x = 1.0, y = 2.0, z = 3.0import numpy as np
A = np.array([[1, 1, -1], [2, -1, 3], [1, 2, 1]], dtype ='int32')
print(np.linalg.det(A))
print(A[0, 0] * np.linalg.det(A[1:, 1:]) - A[0, 1] * np.linalg.det(A[1:, [0, 2]])
+ A[0, 2] * np.linalg.det(A[1:, :2]))
-11.000000000000002
-11.000000000000002
예제:

import numpy as np
print("난수 정수 행렬 생성:")
a = np.random.randint(1, 101, size = (5, 3))
print(a)
b = a[:, 1] >= 60
print(b)
c = np.array(a[b])
print(c)
난수 정수 행렬 생성:
[[23 39 90]
[49 51 39]
[44 90 4]
[60 26 10]
[ 8 83 28]]
[False False True False True]
[[44 90 4]
[ 8 83 28]]
import numpy as np
p1 = np.array([1, 5, 10])
p2 = np.array([2, 4, 6])
d = np.sqrt(np.sum(np.pow(p1 - p2, 2)))
print(d)
4.242640687119285
- slice를 사용하면 해당 행이 살아 있음
- array2[1, 1:]: [5 6] ... (2, )
- array2[1:2, 1:] [[5 6]] ... (1, 2)
array2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(array2[1, 1:])
print(array2[1, 1:].shape)
print(array2[1:2, 1:])
print(array2[1:2, 1:].shape)
print(array2[:2, :2]) # 첫 두 행, 첫 두 열 슬라이싱
print(array2[:2, :2].shape)
[5 6]
(2,)
[[5 6]]
(1, 2)
[[1 2]
[4 5]]
(2, 2)
- array > 25: 벡터화(Vectorization): numpy 원소끼리 연산
import numpy as np
array = np.array([10, 20, 30, 40, 50])
result = array[array>25] # 25보다 큰 값 추출
print(result)array2 = np.array([[10, 20, 30], [40, 50, 60]])
result = array2[array2 > 35] # 35보다 큰 값 추출
print(result)
result = array2[array2 > 25] # 25보다 큰 값 추출
print(result)
[40 50 60]
[30 40 50 60]
- np.where(condition): 조건을 만족하는 요소들의 인덱스를 튜플 형태로 반환
indices = np.where(array > 30) # 30보다 큰 인덱스 추출
print(indices)
print(array[indices]) # 인덱스를 사용하여 값 추출
(array([3, 4]),)
[40 50]
- np.delete(arr, obj, axis=None): 배열에서 특정 위치(인덱스)의 요소를 삭제할 때 사용
array2 = np.array([[1, 2], [3, 4], [5, 6]])
result2 = np.delete(array2, 1, axis=0) # 1번 행(2행) 삭제 -> [[1, 2], [5, 6]]
result3 = np.delete(array2, 0, axis=1) # 0번 열(1열) 삭제 -> [[2], [4], [6]]
print(result2)
print(result3)
[[1 2]
[5 6]]
[[2]
[4]
[6]]
- np.isin(arr, elements): 배열의 각 요소가 특정 값들의 집합에 포함되어 있는지 한 번에 확인할 때 사용하는 함수
array = np.array([10, 20, 30, 40, 50])
result = np.isin(array, [10, 30]) # 10 또는 30이 포함된 값 찾기
print(result)
filtered = array[result] # 조건 만족하는 값만 추출
print(filtered)
[ True False True False False]
[10 30]
- 행렬 곱 연산
- np.matmul(vector1, vector2)
- vector1 @ vector2
- np.dot(vector1, vector2)
import numpy as np
# 두 벡터 정의
vector1 = np.array([[1, 2], [3, 4]])
vector2 = np.array([[4, 5], [5, 6]])
# 벡터 내적 계산
dot_product = np.matmul(vector1, vector2)
print("벡터 내적:", dot_product) # 1*4 + 2*5 + 3*6
dot_product = vector1 @ vector2
print("벡터 내적:", dot_product) # 1*4 + 2*5 + 3*6
dot_product = np.dot(vector1, vector2)
print("벡터 내적:", dot_product) # 1*4 + 2*5 + 3*6
벡터 내적: [[14 17]
[32 39]]
벡터 내적: [[14 17]
[32 39]]
벡터 내적: [[14 17]
[32 39]]
추가:
import numpy as np
v2 = np.arange(1, 16)
# 아래 빈칸을 채워 배열 [14, 11, 8, 5, 2] 가 출력되도록 만들기
result = v2[???]
print(result)# 1. 양수 인덱스를 활용한 정답
result = v2[13::-3]
# 2. 음수 인덱스를 활용한 정답
result = v2[-2::-3]
문제 1: 체스판 패턴 만들기 (고급 슬라이싱)
크기가 8x8이고 모든 요소가 0인 2차원 배열을 생성한 뒤, 슬라이싱 연산만을 사용하여 체스판처럼 0과 1이 교차하는 패턴을 만들어라. 단, [0, 0] 위치의 값은 0이어야 한다.
import numpy as np
mat = np.zeros((8, 8))
print(mat)
mat[::2, ::2] = 1
mat[1::2, 1::2] = 1
print(mat)
[[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]]
[[1. 0. 1. 0. 1. 0. 1. 0.]
[0. 1. 0. 1. 0. 1. 0. 1.]
[1. 0. 1. 0. 1. 0. 1. 0.]
[0. 1. 0. 1. 0. 1. 0. 1.]
[1. 0. 1. 0. 1. 0. 1. 0.]
[0. 1. 0. 1. 0. 1. 0. 1.]
[1. 0. 1. 0. 1. 0. 1. 0.]
[0. 1. 0. 1. 0. 1. 0. 1.]]
문제 2: 다중 조건부 데이터 변경 (불리언 인덱싱 & np.where)
1부터 20까지의 연속된 정수로 이루어진 1차원 배열을 생성하라. 그다음, 15의 배수는 -3, 5의 배수는 -2, 3의 배수는 -1로 원본 배열의 값을 변경하라. (단, 15는 3과 5의 공배수이므로 반드시 -3으로 변경되어야 한다.)
import numpy as np
array = np.arange(1, 21)
print(array)
a = np.where(array % 5 == 0)
b = np.where(array % 3 == 0)
c = np.where(array % 15 == 0)
array[a] = -2
print(array)
array[b] = -1
print(array)
array[c] = -3
print(array)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20]
[ 1 2 3 4 -2 6 7 8 9 -2 11 12 13 14 -2 16 17 18 19 -2]
[ 1 2 -1 4 -2 -1 7 8 -1 -2 11 -1 13 14 -1 16 17 -1 19 -2]
[ 1 2 -1 4 -2 -1 7 8 -1 -2 11 -1 13 14 -3 16 17 -1 19 -2]
문제 1: 배열 생성과 재구성 (reshape, transpose)
np.arange를 사용하여 2부터 24까지의 짝수로 이루어진 1차원 배열을 생성하라. 그 후, 이 배열을 3행 4열(3x4)의 2차원 배열로 재구성(reshape)하고, 만들어진 행렬의 전치(transpose) 행렬을 생성하여 출력하라.
import numpy as np
array = np.arange(2, 25, 2).reshape(3, 4)
print(array)
print(np.transpose(array))
[[ 2 4 6 8]
[10 12 14 16]
[18 20 22 24]]
[[ 2 10 18]
[ 4 12 20]
[ 6 14 22]
[ 8 16 24]]
문제 2: 조건부 데이터 추출 및 변경 (Boolean Indexing)
10부터 100까지 10 단위의 값으로 이루어진 1차원 배열을 생성하라.
- 배열에서 40 이상 80 이하인 값들만 논리 연산자를 사용해 추출하여 출력하라.
- 원본 배열에서 30 이하이거나 90 이상인 값들을 모두 0으로 덮어씌워 변경하라.
import numpy as np
array = np.arange(10, 101, 10)
print(array[(array >= 40) & (array <= 80)])
array[(array <= 30) | (array >= 90)] = 0
print(array)
[40 50 60 70 80]
[ 0 0 0 40 50 60 70 80 0 0]
문제 3: 다차원 배열의 삭제와 슬라이싱 (np.delete, Slicing)
다음과 같은 3x3 크기의 배열을 생성하라. arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) 이 배열에서 2행(인덱스 1 위치의 행)을 np.delete 함수와 axis를 지정하여 삭제한 뒤 새로운 변수에 저장하라. 그 다음, 행이 삭제되고 남은 새 배열에서 두 번째 열(인덱스 1) 전체를 슬라이싱하여 출력하라.
import numpy as np
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
res = np.delete(arr, 1, axis=0)
print(res[:, 1])
[2 8]
문제 4: 축(axis)을 활용한 통계 연산
np.random.randint(1, 50, size=15)를 사용하여 1부터 49 사이의 난수 15개를 생성하고, 이를 3행 5열(3x5) 크기의 배열로 변환하라.
- 이 배열의 열 방향(세로 방향, axis=0)의 합계(sum)를 구하라.
- 이 배열의 행 방향(가로 방향, axis=1)의 최댓값(max)을 구하라.
import numpy as np
arr = np.random.randint(1, 50, size=15).reshape(3, 5)
print(arr)
print(arr.sum(axis=0))
print(arr.max(axis=1))
[[43 22 4 23 32]
[10 35 20 25 21]
[18 28 3 34 15]]
[71 85 27 82 68]
[43 35 34]
문제 5: 선형 연립방정식 풀이와 행렬식 (np.linalg)
다음과 같은 선형 연립방정식이 주어졌다.
$3x + 2y = 12$
$x - y = -1$
- 위 방정식의 계수 행렬 A와 상수 벡터 b를 넘파이 배열로 선언하고, np.linalg.solve 함수를 사용하여 해(x, y)를 구하라.
- 계수 행렬 A의 행렬식(determinant)을 np.linalg.det 함수를 사용하여 구하라.
import numpy as np
a = np.array([[3, 2], [1, -1]])
b = np.array([12, -1])
c = np.linalg.solve(a, b)
print(f"x = {c[0]:.2f}, y = {c[1]:.2f}")
print(f"determinant: {np.linalg.det(a):.2f}")
x = 2.00, y = 3.00
determinant: -5.00'4. University Study > Advanced Python Programming' 카테고리의 다른 글
| [Advanced Python Programming] Lecture 12. Pandas (0) | 2026.05.24 |
|---|---|
| [Advanced Python Programming] 중간고사 암기 (0) | 2026.04.17 |
| [Advanced Python Programming] Lecture 10. Exception Handling (1) | 2026.04.17 |
| [Advanced Python Programming] Lecture 9. File Input/Output (0) | 2026.04.17 |
| [Advanced Python Programming] Lecture 8. Module and Package (0) | 2026.04.16 |


