

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Language model
- do it! 알고리즘 코딩테스트: c++편
- marchine learning
- underfiting
- numpy
- tree purning
- Baekjoon
- 딥러닝
- boosting for classification
- model selection
- jini impurity
- Backtracking
- DFS
- BFS
- Linear Regression
- Machine Learning
- 고전소설
- word2vec
- 밑바닥부터 시작하는 딥러닝2
- overfiting
- boosting for regression
- classification
- dynamic programming
- RNN
- SQLD
- 밑바닥부터 시작하는 딥러닝
- C++
- deep learning
- Python
- CBOW
- Today
- Total
newhaneul
[ML/DL: Prof. Joonseok Lee] Lecture 8. Decision Trees 본문
[ML/DL: Prof. Joonseok Lee] Lecture 8. Decision Trees
뉴하늘 2025. 3. 9. 20:09본 포스팅은 서울대학교 이준석 교수님의 M3239.005300 Machine Learning & Deep Learning 1을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
이준석 교수님에게 강의 자료 사용에 대한 허락을 받았음을 알립니다.
https://youtu.be/KNBP2KkN-ug?si=YgV6MG8UzvQGALEr
1. Decision Trees
Decision Tree는 데이터를 기반으로 의사결정을 위한 규칙을 트리(Tree) 형태로 표현하는 Supervised Learning 알고리즘이다.
일련의 조건 분할을 통해 데이터를 여러 개의 subtree들로 나누어 예측을 수행한다. 이는 사람의 의사결정 과정과 유사하며, Classification과 Regression Problem 모두 해결할 수 있다.

Decision Tree Alogrithm은 Step 1과 Step 2로 구분할 수 있다.
먼저, Step 1에서는 가능한 x의 모든 값들을 여러개의 non-overlapping하는 Region들로 쪼갠다.
Step 2는 각각의 Region들이 같은 prediction을 갖도록 설정한다.

Step 1.
RSS를 최소화시키는 J개의 region으로 분할해야 하는 것이 궁극적인 목적이다. 하지만 모든 경우의 수를 계산하여 J를 구한다면 계산량이 너무 많아지게 되기 때문에 top-down과 greedy apporach를 활용한다.
Top-down은 tree의 root에서부터 leap까지 순차적으로 분리하는 것을 말한다.
Greedy는 Algorithm 중 하나로서 최종 결과가 최적의 결과가 아닐지라도, 매 순간마다 최적의 값으로 분할하는 것이다.

분리되는 region을 R1, R2라고 하면, R1은 x가 s보다 작을 경우, R2는 x가 s보다 크거나 같을 경우의 region이라고 할 수 있다. 그러면, R1과 R2의 RSS를 최소화시키는 값인 s를 구하고, 이 s로 분할하면 될 것이다.
또 overfiting을 방지하기 위해 region 개수를 미리 정해놓는다거나 하나의 region에 특정 값보다 작은 x가 들어갈 경우 split을 멈추는 방법을 채택한다.

아래의 예시에서는 R1과 R2 region의 RSS 최솟값을 구해본 결과 5.2가 최택된 모습을 볼 수 있다.

Step 2.
Step 1에서 x들을 각각의 region으로 분리했다면, 단순하게 하기 위해 각 region의 x들이 모두 같은 값을 갖도록 하는 상수 값을 할당해야 한다. 단순해 보일수도 있지만 충분히 각각의 region이 작아지게 되면, 상수는 합리적인 방법이 될 수 있다.
RSS를 최소화하는 상수 c를 구하는 방법을 알아보도록 한다.

RSS를 최소가 되도록 하는 상수 c를 구하기 위해 MLE를 진행하도록 한다. MLE를 통해 전개하게 되면 상수 c는 각 region에 있는 training examples의 평균이 되어야 함을 알 수 있다.


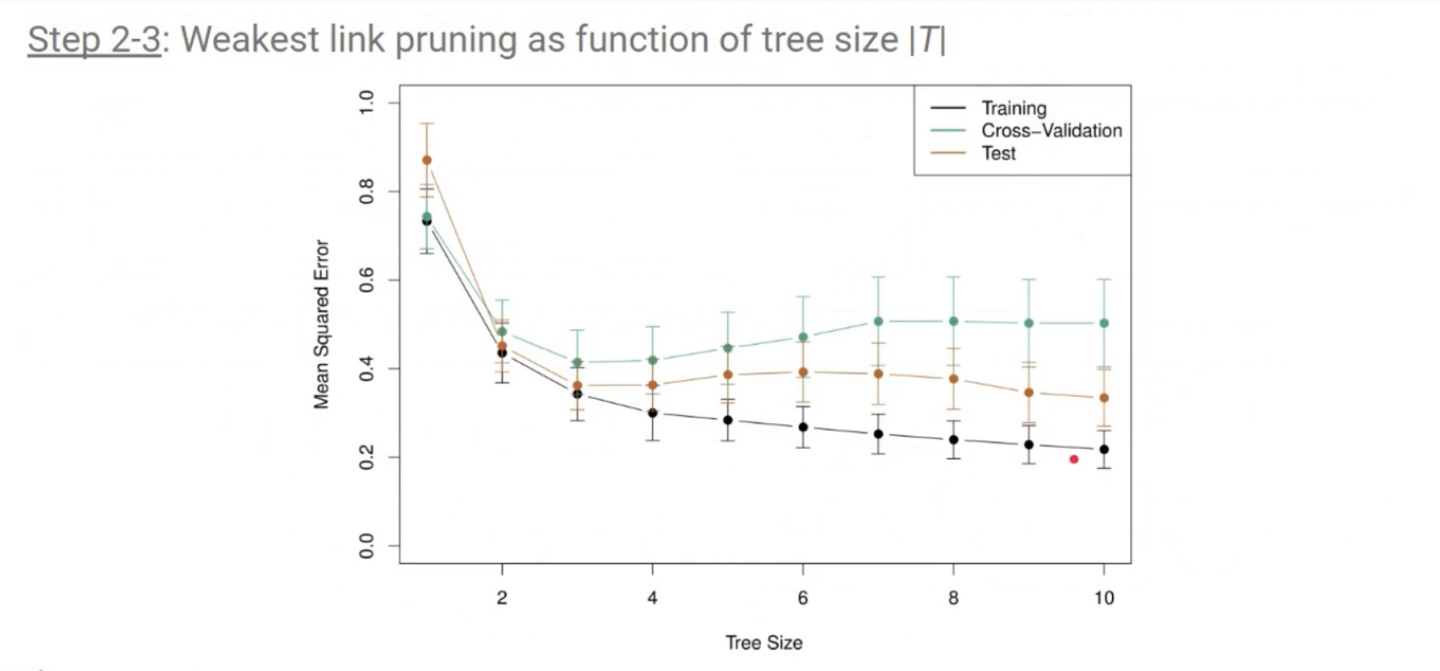
2. Tree Pruning
Tree Pruning은 decision tree가 overfitting이 되지 않도록 방지하는 기법이다. Decision Tree는 Greedy Algorithm을 활용하고 있기 때문에 초기에 Tree의 한계 depth를 설정하여 중간에 split을 멈추게 되면 성능이 잘 나오지 않을 수 있다.

따라서 가장 큰 decision tree를 만든 후에 prune을 진행해 작아지게 만드는 방법을 채택한다. 방법은 L1 Regularization의 penalty-term과 비슷하다.

- |T|: leaf nodes의 개수
- α : training data 학습 효과와 tree의 complexity 간의 trade-off parameter(L1 Regularization에서의 λ 역할)



3. Classification Trees
지금까지의 Decision Tree는 Regression Problem에 관한 내용이였다. 이번엔 Classification Problem에 관한 내용을 알아보도록 한다. Decision Tree는 Regression과 Classification Algorithm이 거의 동일하다.

Step 1.
Classification Step 1에서는 각각의 region의 Classification Error를 최소화시키는 조건 s를 구하도록 한다. Impurity는 분할한 region이 얼마나 pure한지를 알려주는 함수이다. 즉, Impurity가 작을수록 완벽하게 분리됨을 의미한다. n1과 n2로 나누는 이유는 size가 큰 region으로 분할하는 것을 선택하기 위해 나누어 준다.

Impurity 함수에는 Entropy 함수가 있다. 이는 불확실성을 측정하는 지표로 0에 가까울 수록 가장 pure함을 의미하고 1에 가까울수록 가장 impure한 상태이다.

또 다른 Impurity 함수로 지니 불순도(Gini Impurity)가 있다. 이는 특정 데이터셋이 얼마나 혼합되어 있는지를 측정하는 값이다. 주로 경제학에서 사용하는 지표이다. Entropy와 마찬가지로 0에 가까울수록 pure한 상태을 의미한다.

Step 2.
Classification에서는 각 region의 class들 중 region에 가장 많이 포함되어 있는 class로 region을 할당한다.(ex: 다수결)


Decision Tree는 사람이 의사결정을 하는 것과 유사하게 작동되므로 해석하기가 편하고, 시각적으로 표현하기 편한 방식이다. 또한 쉽게 연속형 predictors를 다룰 수 있다.
단점으로는 predictive accuracy가 떨어지고, 이상치나 데이터의 변화에 크게 영향을 받는다.




