| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- BFS
- computer vision
- DFS
- Generative Models
- marchine learning
- 밑바닥부터 시작하는 딥러닝
- assignment1
- assignment2
- 딥러닝
- Optimization
- Multi-Head Attention
- CNN
- do it! 알고리즘 코딩테스트: c++편
- Regularization
- SQLD
- RNN
- Algorithm
- mask r-cnn
- deep learning
- 밑바닥부터 시작하는 딥러닝2
- Machine Learning
- Baekjoon
- Adam
- Alexnet
- dropout
- CPP
- C++
- cs231n
- Transformer
- Python
- Today
- Total
newhaneul
[Seoul National Univ: ML/DL] Lecture 7. Overfitting & Regularization 본문
[Seoul National Univ: ML/DL] Lecture 7. Overfitting & Regularization
뉴하늘 2025. 3. 7. 18:35본 포스팅은 서울대학교 이준석 교수님의 M3239.005300 Machine Learning & Deep Learning 1을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
이준석 교수님에게 강의 자료 사용에 대한 허락을 받았음을 알립니다.
https://youtu.be/5nVeXPeGDYM?si=frW4h8M9FPCF00Oc
1. Overfitting
Overfitting(과적합)은 Model이 훈련 데이터에 너무 잘 맞춰져서 Test Data에서 좋은 성능을 내지 못하는 현상을 의미한다.

Model Capacity란 Model Complexity와 동의어이다. 일반적으로 parameter(β)의 개수와 model의 복잡성이 커질수록 Model Capacity가 증가한다. 이는 model이 Training data의 noise에 대해서도 학습해버리는 Overfitting 현상이 발생하게 된다. 반대로, Model Capacity가 낮으면 model이 Training data의 일반적인 패턴을 학습하지 못해 Underfiting 현상이 발생한다. 따라서 적절한 Model Capacity를 찾는 것이 ML/DL에서 중요한 과제이다.
Dataset이 I.I.D assumption을 만족한다고 가정하면, dataset이 너무 작지 않는한 training data의 overfiting 발생 시점과 validation data의 overfiting 발생 시점이 동일하다고 생각할 수 있다.

Training을 멈추는 방법에는 2가지 방법이 있다.
1. Validation set의 loss가 커지는 시점에서 학습을 멈춘다.
Early Stopping 기법이라고도 불린다. 이 기법은 모델이 훈련을 진행하면서 검증 데이터셋(Validation set)에 대한 손실(loss)이 증가하는 시점을 감지하여 학습을 중지한다.
2. Classification Accuracy가 떨어지는 시점에서 학습을 멈춘다.
Classification Accuracy는 모델이 훈련을 진행하면서 Test set 또는 Validation set에 대한 정확도가 감소하기 시작하면 학습을 멈춘다.
-> Validation set의 loss가 커지는 시점이 실제 metric이 overfit되는 시점과 같지 않을 수 있다. 따라서 Training을 멈추는 시점은 Classification Accuracy로 판단하는것이 적절하다.

실제 metric이 overfit이 되는데도 loss는 overfit되지 않는 상황이 있을 수 있다. 따라서 가능하면 training을 멈추는 시점을판단할 때 validation loss에 의존하는 것은 좋지 않다.
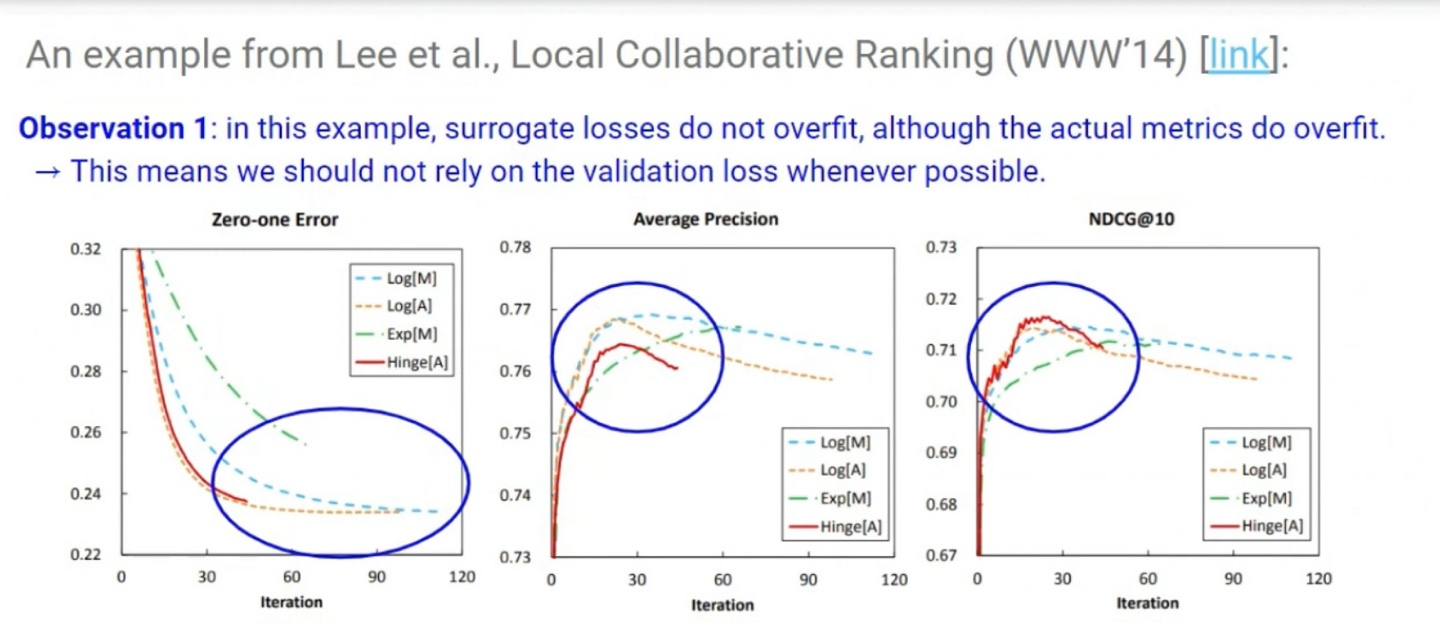
각 metric의 overfit 시점은 서로 다르다. 따라서 보통 Early Stopping 시점을 결정할 때 가장 중요하게 생각하는 metric이 overfit 되는 시점을 기준으로 삼는다.

2. Regularization
1. Model Selection
Model Selection을 할 때 가장 복잡한 모델을 general model이라고 가정하고 학습 하는 과정에서 복잡한 모델의 parameter을 0에 가까워지도록 유도하는 방법이다.
어차피 단순한 모델은 복잡한 모델의 parameter 몇 개가 0인 모델이므로 이 방법이 가능한 것이다.

2. Shrinkage Methods
General model(복잡한 모델)의 coefficient estimates가 0에 가깝게 줄어들도록 하는 기술이다. 즉, 모델의 복잡도를 제어하고 overfitting을 방지하기 위해 parameter를 일정 부분 축소하거나 제한하는 기법들이다.

3. Ridge Regression(L2 Regularization)
Ridge Regression(L2 Regularization)은 회귀 모델에서 가중치의 크기를 작게 만드는 기법이다. L2 정규화는 모든 파라미터의 제곱 합에 대한 페널티를 부여하여 모델을 단순화시킨다.


하이퍼파라미터는 정규화 강도를 조절한다. λ 값이 클수록 회귀 계수에 더 큰 패널티가 부여되어, 가중치가 더 작아지며 모델이 더 단순화된다. 반대로 λ값이 작으면, 회귀 계수들이 최소제곱법을 따르듯이 훈련된다.
λ = 이면 일반 선형 회귀가 되며, λ값이 커질수록 모델은 더 강하게 정규화된다.

Ridge Regression에서 X에 Standardizing을 적용해야 한다. Ridge Regression의 Coefficient estimates들 간의 Scale 차이를 equivariant하게 만들어 모델 학습의 효율성과 성능을 높이기 위해서이다.
Ridge Regression은 L2 정규화(penalty term)를 사용하여 가중치(회귀 계수)를 축소하는데, 특성들이 서로 다른 Scale을 가지면 정규화가 불균형하게 적용될 수 있다. 이로 인해 학습 과정에서 불안정성이나 잘못된 해석을 초래할 수 있다.
그래서 Standardizing을 통해 모든 특성들이 비슷한 범위를 가지게 만들어, 정규화가 균등하게 적용될 수 있도록 한다.

Ridge Regression에 MLE를 계산하여 정리한 방정식은 선형 회귀의 MLE 방정식에 정규화 Term을 추가한 것이다. 이 추가된 term은 모델의 가중치를 작게 유지하려고 하며, 그 결과 Overifit을 방지하고 모델의 성능을 더 일반화된 형태로 만든다. 회귀 계수 β다음의 정규 방정식으로 구할 수 있다:


2차원에서 Ridge Regression의 최적화 과정을 시각화하면, 파라미터 공간에서 원(circle) 형태로 나타날 수 있다. 이를 이해하기 위해 β norm의 제곱 term을 이해해야한다.
β norm의 제곱 term에 의해 가중치 벡터의 크기를 제약하며, 이로 인해 parameter(β)들이 원 형태로 제약을 받게 된다. 원은 특정한 크기의 가중치 벡터들에 대한 제약을 의미하며, 이로 인해 파라미터들이 0에 가까워지는 방향으로 최적화된다.


4. Lasso(L1 Regularization)
Lasso(Least Absolute Shrinkage and Selection Operator)는 Linear Regression에 L1 Regularization를 추가한 기법이다. 이는 β의 크기를 줄이고 일부 계수를 정확히 0으로 만드는 특성을 가지고 있다. 즉, 불필요한 특성을 제거하여 모델을 더 간결하게 만들고 해석 가능성을 높이는 효과가 있다.
Lasso의 경우 Ridge Regression과는 달리 Regularization term(penalty term)을 β의 절댓값 합으로 나타낸다.


Ridge regression은 coefficient estimates들을 0에 가깝게 만들 뿐 0이 되도록 하지는 못하지만, Lasso는 λ가 충분히 클 경우 coefficient estimates들을 0으로 만들 수 있다. 따라서 Ridge regression보다 불필요한 특성을 더 잘 제거할 수 있는 Reguarization이다.


Lasso Regularization을 2차원 공간에서 시각적으로 해석하면, 제약 조건이 마름모(diamond) 형태로 표현된다. 이 마름모는 Lasso가 허용하는 parameter 값의 공간을 제한한다.

Lasso의 마름모 모양이 좌표축과 정렬되어 있으므로, 최적화 과정에서 coefficient estimates 중 일부가 정확히 0이 된다. 아래 그림을 보듯 Lasso는 대부분의 point들을 2차원 공간에서 꼭짓점에 수렴하도록 만들고, 이는 coefficient estimates가 0이 됨을 의미한다.

다차원 data에서도 Lasso는 일부 coefficient estimates들을 0으로 만들어 불필요한 변수를 제거하므로 Ridge regression보다 더 sparser model을 만든다. sparser model은 불필요한 요소가 제거된, 더 간결하고 해석 가능한 모델을 의미한다.
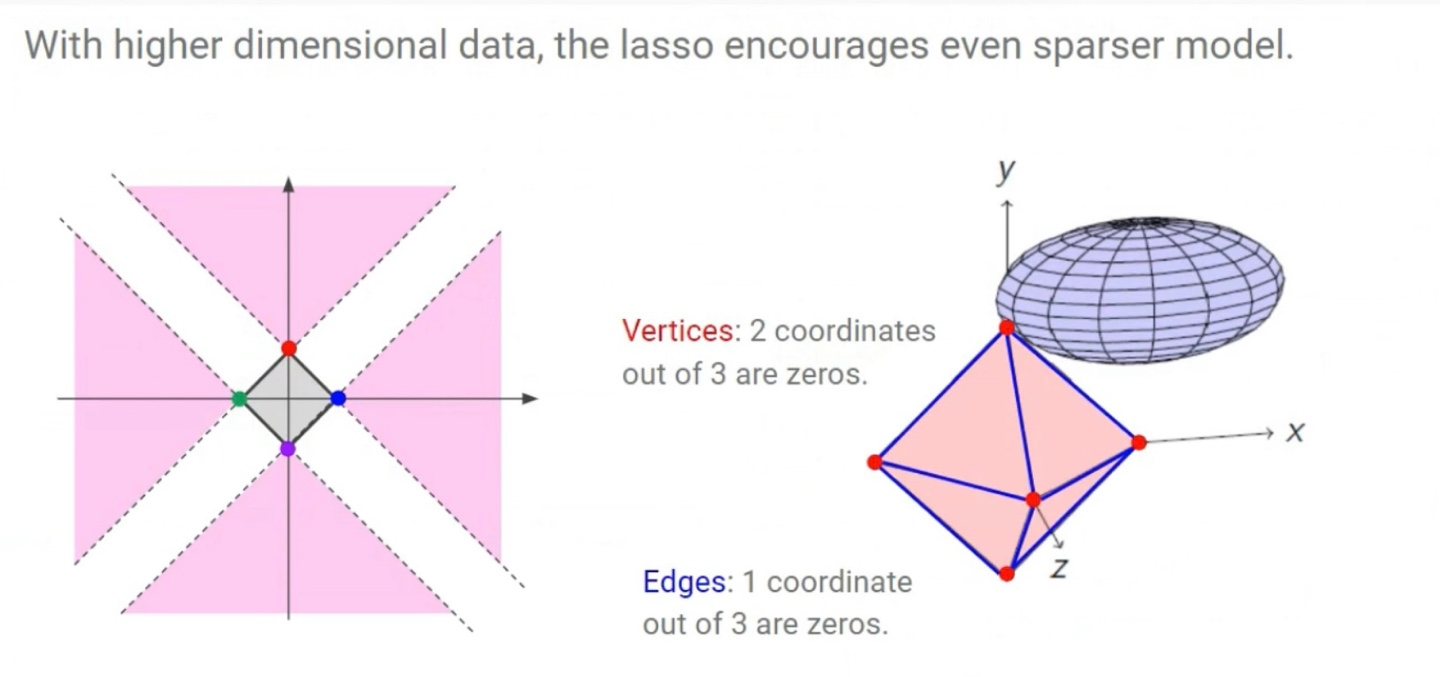
Ridge Regression과 Lasso는 data set에 따라 다르므로 둘 중 어느것이 더 뛰어나다고 비교하기 어렵다. 실제 data set의 특성과 목적에 따라 적절한 방법을 선택하는것이 옳다.

5. Finally