
- 분류 전체보기 (187)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- On-memory file system
- DFS
- SQLD
- Data Science
- Baekjoon
- Linux
- Seoul National University
- file system
- Gentoo2
- Process
- Machine Learning
- cs231n
- ROS2
- Multimedia
- RNN
- CNN
- BFS
- Robocup@Home 2026
- System Call
- C++
- paper review
- Optimization
- computer vision
- Operating System
- CPP
- 밑바닥부터 시작하는 딥러닝2
- do it! 알고리즘 코딩테스트: c++편
- Python
- deep learning
- Humble
- Today
- Total
newhaneul
[Multimedia] Lecture 5. Vertex Shader 본문
본 포스팅은 인하대학교 안남혁 교수님의 [202601-EEC4410-001] Multimedia을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
1. GPU Rendering Pipeline

- 3D 물체를 2D 화면에 표현하기 위해 일련의 렌더링 파이프라인 구조를 채택한다.
- Vetex Shader -> Rasterizer -> Fragment Shader -> Output Merger
- 파이프라인 중 Vertex Shader와 Fragment Shader는 사용자가 프로그래밍이 가능한 단계로 분류된다.
- 반면에 Rasterizer와 Output Merger는 GPU 하드웨어에 미리 정의된 지시사항에 따라 고정된 연산만을 수행하게 된다.
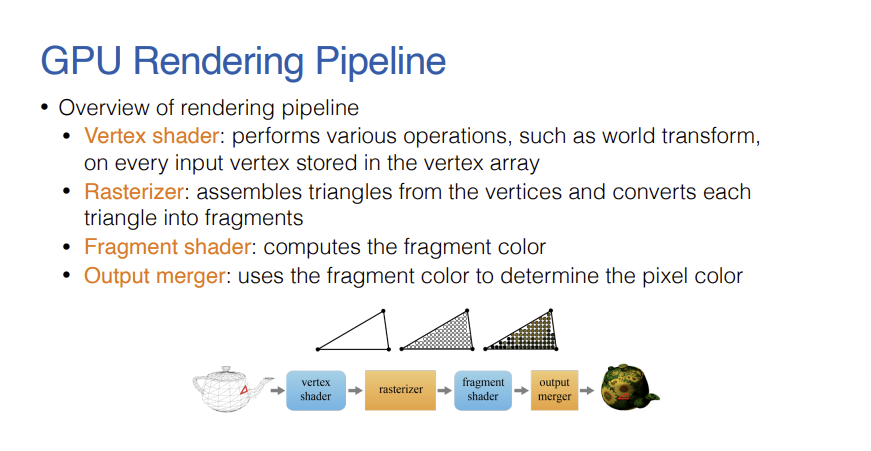
- Vertex Shader는 배열에 저장된 각각의 정점(Vertex)을 하나씩 가져와 공간 변환 등의 핵심 작업을 수행한다.
- Rasterizer는 변환된 정점들을 이어 삼각형(Triangle)을 구성하고, 이를 다시 수많은 Fragment 단위로 분할한다.
- Fragment Shader는 분할된 개별 Fragment의 색상을 정밀하게 계산하며, 마지막으로 Output Merger가 이 값을 활용하여 화면에 표시될 최종 픽셀 색상을 결정한다.
** 2024-2 퀴즈 **

- 정답: O
2. Geometry Pipeline 및 Space Transformation

- 기하학적 파이프라인에서 가장 본질적인 연산은 정점에 다수의 변환(Transform) 과정을 순차적으로 적용하는 과정에 해당한다.
- Object Space: 모델링 단계에서 각 물체가 독립적으로 지니고 있는 고유의 좌표계를 의미한다.
- World Space: 렌더링 세계에 존재하는 모든 물체를 통합하여 표현하는 절대 좌표 공간이며, World Transform을 통해 개별 Object Space의 좌표를 이 공간으로 변환한다.

- Camera Space: 가상의 카메라 위치를 좌표계의 원점으로 삼고 카메라가 바라보는 방향을 -z축으로 설정한 공간을 뜻한다. 물체 렌더링 연산을 단순화하기 위해 View Transform 행렬을 사용하여 World Space의 점들을 카메라 기준으로 변환한다.
- Clip Space: 최종적으로 모니터 스크린 영역에 출력될 픽셀들을 정의하는 공간이며, Projection Transform을 거쳐 원근감이 반영된 기하학적 구조로 물체를 변환한다.
** 2024-2 퀴즈 **
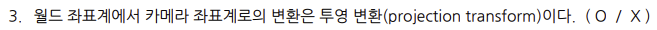
- 정답: X (View Transform)
** 2024-2 퀴즈 **

- 정답:
- 1. World Transform (Object Space $\rightarrow$ World Space): 개별 물체들이 각자 고유한 중심점과 좌표계를 갖는 Object Space에서, 하나의 통합된 월드 공간 내로 배치하는 과정이다. 해당 과정을 거치면 독립적이었던 모든 물체가 동일한 월드 좌표계를 기준으로 표현된다.
- 2. View Transform (World Space $\rightarrow$ Camera Space): 월드 공간에 배치된 물체들을 가상 카메라 (관찰자)의 시점을 기준으로 재정렬한다. 관찰자 중심으로 공간을 재편함으로써 이후의 렌더링 파이프라인 연산이 수월해진다.
- 3. Projection Transform (Camera Space $\rightarrow$ Clip Space): Camera Space의 물체들을 2D 화면에 투영하기 위해 View Frustum을 정의하고, 이를 정규화된 큐브 형태로 일그러뜨려 변환하는 과정에 해당된다.
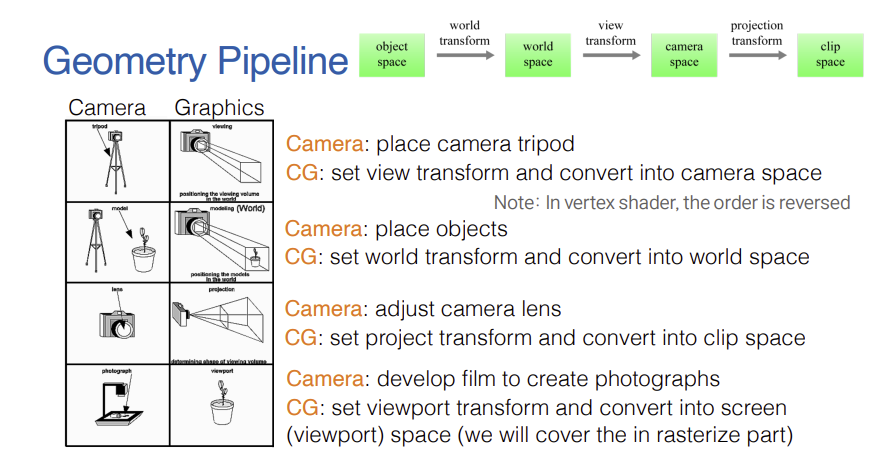
- 이러한 변환 파이프라인은 실제 세상에서 피사체를 알맞은 장소에 배치하고(World Transform), 삼각대 위에서 카메라 방향을 설정하며(View Transform), 카메라 렌즈를 조작하여 화면을 결정하는(Projection Transform) 일련의 촬영 과정과 매우 유사하게 동작한다.
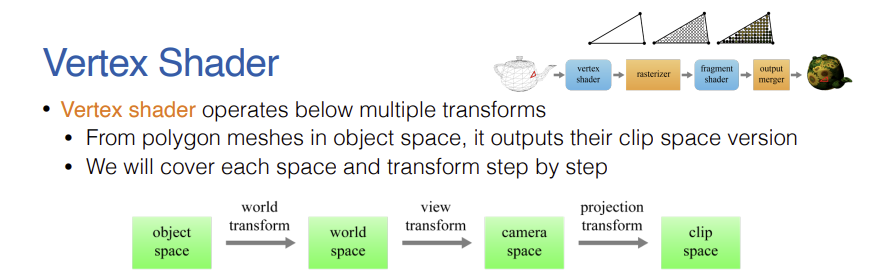
3. World Transform (Object Space $\rightarrow$ World Space)
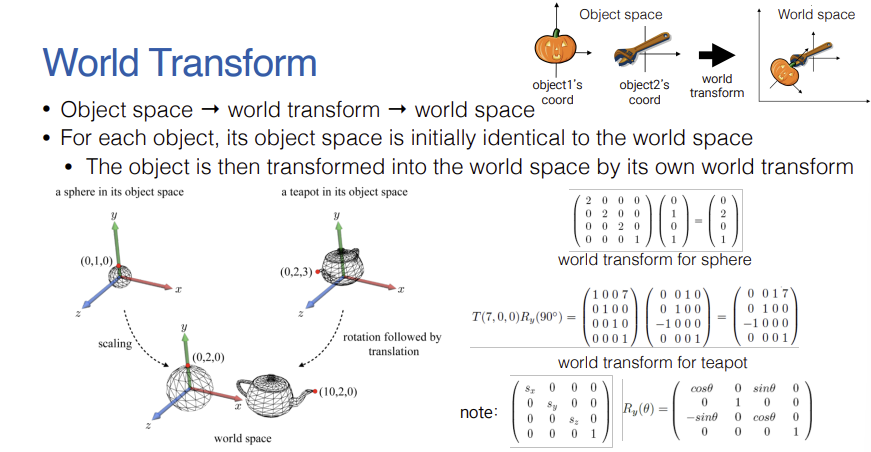
- 각 3D 객체는 고유의 기준점과 축을 가진 객체 공간에서 모델링된다.
- 처음에는 객체 공간과 월드 공간이 동일하지만, 객체마다 고유의 월드 변환 행렬(크기 조절, 회전, 이동 등)을 적용하여 최종적으로 월드 공간 내의 적절한 위치와 형태로 배치하게 된다.

- 물체의 기저 벡터는 초기 생성 시 World Space의 표준 기저인 ${e_1, e_2, e_3}$와 동일하지만, 변환을 통해 자신만의 직교 기저 ${u, v, n}$을 가지게 된다.
- 회전 행렬 $R$이 주어지면, 해당 행렬의 각 열(Column)은 회전된 물체의 직교 기저 $u, v, n$ 방향 벡터를 그대로 나타내게 된다.

- 회전 행렬 $R$을 World Space의 표준 기저 벡터 $(1,0,0)^T$ 등에 곱하면, 새로운 Object Space의 기저 벡터인 $u, v, n$의 각 성분을 얻을 수 있다.
- 이를 행렬로 묶어 표현하면, 회전 행렬 $R$의 결과 행렬 자체가 객체의 방향 벡터들을 열(column)로 가지는 결과 행렬 자체가 $3 \times 3$ 행렬로 구성됨을 알 수 있다.

- 앞선 수식에 따라, 회전 행렬 $R$을 구성하는 각 열(column)은 그대로 Object Space의 축 벡터 $u, v, n$이 된다.
- 객체가 바라보는 방향(축 벡터)을 알고 있다면 이를 열 벡터로 나열하여 회전 행렬을 즉각적으로 만들어낼 수 있고, 반대로 주어진 회전 행렬의 열을 읽어서 객체가 어느 방향을 향하고 있는지 바로 파악할 수 있게 된다. y축 기준 $90^\circ$ 회전 행렬 예시를 통해 이를 확인한다.

- World Space의 좌표계는 표준 기저 ${e_1, e_2, e_3}$를 따른다.
- Object Space의 좌표계 벡터 ${u, v, n}$을 안다면 그것을 열 벡터로 삼아 World Trasnform 행렬(회전 부분)을 구성할 수 있으며, 반대로 World Transform 행렬이 주어지면 그 안에서 Object Space의 좌표계 축 벡터들을 즉시 추출해낼 수 있게 된다.

- 법선(Normal)은 위치가 없는 벡터이므로 이동(Translation, $\mathbf{t}$) 변환에는 영향을 받지 않고 오직 선형 변환 행렬 $\mathbf{L}$(회전 및 크기 조절)에만 영향을 받는다.
- 만약 선형 변환 행렬 $\mathbf{L}$에 각 축의 비율이 다른 비균등 크기 변환(non-uniform scaling)이 포함되어 있을 때, 정점 위치 변환과 동일하게 $\mathbf{L}$을 법선 벡터에 그대로 곱하면 변환된 표면과 법선 벡터가 더 이상 직교(Orthogonal)하지 않게 되는 심각한 문제가 발생한다.
- 따라서 일반적으로는 실수하지 않기 위해 비균등 크기 변환이 포함되어 있다고 가정하고 역행렬의 전치 행렬을 곱한다.

- 변환 후에도 법선 벡터가 항상 표면(삼각형)과 수직을 이루게 하려면, 기존 변환 행렬 $\mathbf{L}$ 대신 역행렬의 전치 행렬인 $\mathbf{L}^{-T}$ (Inverse Transpose)를 곱해주어야 한다.
- 알고리즘의 일관성과 단순화를 위해 일반적으로 법선 변환에는 항상 $\mathbf{L}^{-T}$를 사용하며, 방향 벡터의 길이를 1로 맞추기 위해 최종적으로 정규화(Normalize) 과정을 거쳐야 한다.
** 2024-2 중간고사, 2025-1 중간고사 **


- 정답: Normal vector는 공간상의 특정 위치를 가리키는 것이 아니라 표면의 '방향'만을 나타내는 방향 벡터로 정의된다. 따라서 X축으로 2만큼 이동하는 위치 변환은 벡터의 방향에 어떠한 영향도 주지 않으므로 변환 행렬 계산에서 완전히 제외된다. 문제에서 homogeneous coordinate를 고려하지 않아도 된다고 명시된 이유 역시, 방향 벡터에는 평행 이동 성분이 무의미하기 때문으로 해석된다.
- 주어진 조건에서 방향과 크기에 영향을 주는 Scale 변환 행렬 $M$은 다음과 같이 정의된다.
$$M = \begin{pmatrix} 2 & 0 \\ 0 & 1/2 \end{pmatrix}$$ - 해당 행렬의 역행렬$M^{-1}$을 계산하면 다음과 같이 도출된다.
$$M^{-1} = \begin{pmatrix} 1/2 & 0 \\ 0 & 2 \end{pmatrix}$$ - 대각 행렬은 전치(Transpose)를 취해도 그 값이 변하지 않으므로, 최종적으로 Normal vector에 적용할 행렬 $(M^{-1})^T$는 역행렬과 완전히 동일한 형태를 가지게 된다.
$$(M^{-1})^T = \begin{pmatrix} 1/2 & 0 \\ 0 & 2 \end{pmatrix}$$
- 주어진 조건에서 방향과 크기에 영향을 주는 Scale 변환 행렬 $M$은 다음과 같이 정의된다.
4. View Transform (World Space $\rightarrow$ Camera Space)

World Space 내에서 카메라의 포즈(위치+방향)를 지정하기 위해 세 가지 요소를 정의한다.
- EYE: 카메라의 현재 위치 (Camera Origin).
- AT: 카메라가 초점을 맞추고 바라보는 기준점.
- UP: 카메라의 상단이 향하는 방향을 나타내는 벡터(보통 월드 공간의 y축을 사용함).

주어진 EYE, AT, UP 벡터를 통해 실제 수학적 연산에 쓰이는 카메라 공간의 직교 기저(Orthonormal basis) ${u, v, n}$을 도출하는 핵심 공식을 담고 있는 슬라이드이다.
- n (Z축 대응): EYE - AT를 정규화하여 카메라가 바라보는 반대 방향(오른손 좌표계 기준) 벡터를 구한다.
- u (X축 대응): UP과 n의 외적(Cross product)을 정규화하여 카메라의 오른쪽 방향 벡터를 구한다.
- v (Y축 대응): n과 u의 외적을 통해 카메라의 진정한 위쪽 방향 벡터를 완성한다.
- 이렇게 구해진 ${u, v, n, \mathbf{EYE}}$가 완벽한 카메라 공간을 구성하게 된다.
-
$$\mathbf{A} \times \mathbf{B} = \det \begin{pmatrix} \mathbf{i} & \mathbf{j} & \mathbf{k} \\ a_1 & a_2 & a_3 \\ b_1 & b_2 & b_3 \end{pmatrix}$$
$$\mathbf{A} \times \mathbf{B} = (a_2 b_3 - a_3 b_2, \quad a_3 b_1 - a_1 b_3, \quad a_1 b_2 - a_2 b_1)$$
-

동일한 점이라도 World Space와 Camera Space에서 서로 다른 좌표를 가짐을 보여준다 (예: AT 지점). World Space의 모든 물체를 Camera Space 기준으로 변환하면 렌더링 알고리즘을 개발하기 훨씬 쉬워지기 때문에 View Transform을 수행해야 한다.

공간의 변환을 Camera Space와 World Space를 겹치는(Superimposing) 과정으로 직관적으로 묘사할 수 있다.
- 1단계: 카메라의 위치(EYE)를 World Space의 원점(O)으로 평행 이동(Translation)시킨다.
- 2단계: 카메라의 축 ${u, v, n}$을 월드 축 ${e_1, e_2, e_3}$에 일치하도록 회전(Rotation)시킨다.

앞서 설명한 1단계(이동)에 대한 수학적 행렬 $T$를 보여준다.
- EYE를 원점으로 보내야 하므로, 행렬의 마지막 열에 $-EYE_x, -EYE_y, -EYE_z$의 이동 값이 들어간다.

- 월드 축을 카메라 축으로 회전시키는 행렬을 구해야 한다. 회전 행렬 $R$은 직교 행렬이므로 그 역행렬이 곧 전치행렬($R^{-1} = R^T$)과 같다는 성질을 이용한다.
- 결과적으로 카메라의 기저 벡터 $u, v, n$의 각 성분을 $R$ 행렬의 각 '행(Row)'에 그대로 배치하기만 하면 역회전 행렬이 완성된다.

최종적으로 파이프라인에 적용되는 단일 뷰 변환 행렬 $M_{view}$의 완성된 수식은 위와 같다.
- 회전 행렬 $R$과 이동 행렬 $T$를 곱하여($M_{view} = RT$) 하나의 통합된 4x4 행렬을 만든다.
- 이 $M_{view}$ 행렬 하나를 World Space의 모든 물체에 곱함으로써 전체 씬(Scene)을 Camera Space으로 완벽히 변환하게 된다.
** 2024-2 중간고사 **

- 정답: Point $(2, -1, 0)$은 뷰 변환에 의해 카메라 좌표계의 $(-1, 2, 2)$로 변환된다.
- 1. 주어진 파라미터 식별
- 카메라 위치 $\mathbf{EYE} = (0, 0, -2)$
- 카메라 기저 벡터 $\mathbf{u} = (0, 1, 0)$
- 카메라 기저 벡터 $\mathbf{v} = (1, 0, 0)$
- 카메라 기저 벡터 $\mathbf{n} = (0, 0, 1)$
- 변환할 월드 좌표계의 점 $\mathbf{P} = (2, -1, 0)$
- 2. 이동 행렬 ($T$) 계산
- 카메라의 위치(EYE)를 월드 좌표계의 원점으로 평행 이동시키는 행렬 $T$는 다음과 같이 정의된.
$$T = \begin{pmatrix} 1 & 0 & 0 & -\text{EYE}_x \\ 0 & 1 & 0 & -\text{EYE}_y \\ 0 & 0 & 1 & -\text{EYE}_z \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 2 \\ 0 & 0 & 0 & 1 \end{pmatrix}$$
- 카메라의 위치(EYE)를 월드 좌표계의 원점으로 평행 이동시키는 행렬 $T$는 다음과 같이 정의된.
- 3. 회전 행렬 ($R$) 계산
- 월드 좌표계의 축을 카메라 좌표계의 기저 벡터 $u, v, n$에 맞추어 회전시키는 행렬 $R$은 다음과 같이 구성된다.
$$R = \begin{pmatrix} u_x & u_y & u_z & 0 \\ v_x & v_y & v_z & 0 \\ n_x & n_y & n_z & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}$$
- 월드 좌표계의 축을 카메라 좌표계의 기저 벡터 $u, v, n$에 맞추어 회전시키는 행렬 $R$은 다음과 같이 구성된다.
- 4. 뷰 변환 행렬 ($M_{view}$) 도출
- 두 행렬을 곱하여 최종 뷰 변환 행렬 $M_{view}$를 계산한다.
$$M_{view} = R \cdot T = \begin{pmatrix} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 2 \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 2 \\ 0 & 0 & 0 & 1 \end{pmatrix}$$
- 두 행렬을 곱하여 최종 뷰 변환 행렬 $M_{view}$를 계산한다.
- 5. 점 $\mathbf{P}$에 뷰 변환 적용
- 점 $\mathbf{P}(2, -1, 0)$를 4차원 동차 좌표계(Homogeneous coordinate)인 $(2, -1, 0, 1)^T$로 변환한 후, $M_{view}$를 곱하여 최종 좌표를 구한다.
$$\mathbf{P}' = M_{view} \cdot \mathbf{P} = \begin{pmatrix} 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 2 \\ 0 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} 2 \\ -1 \\ 0 \\ 1 \end{pmatrix} = \begin{pmatrix} 0\cdot2 + 1\cdot(-1) + 0\cdot0 + 0\cdot1 \\ 1\cdot2 + 0\cdot(-1) + 0\cdot0 + 0\cdot1 \\ 0\cdot2 + 0\cdot(-1) + 1\cdot0 + 2\cdot1 \\ 0\cdot2 + 0\cdot(-1) + 0\cdot0 + 1\cdot1 \end{pmatrix} = \begin{pmatrix} -1 \\ 2 \\ 2 \\ 1 \end{pmatrix}$$
- 점 $\mathbf{P}(2, -1, 0)$를 4차원 동차 좌표계(Homogeneous coordinate)인 $(2, -1, 0, 1)^T$로 변환한 후, $M_{view}$를 곱하여 최종 좌표를 구한다.
- 1. 주어진 파라미터 식별
** 2025-1 중간고사 **

- 정답:
- (a) Camera space의 원점(origin)과 기저(basis)
- Origin (원점): $(0, 0, -\sqrt{3})$
- 카메라 공간의 원점은 카메라의 위치인 $\mathbf{EYE}$와 동일하게 설정된다.
- $n$ 벡터 (Z축 대응)
$$n = \frac{\mathbf{EYE} - \mathbf{AT}}{\|\mathbf{EYE} - \mathbf{AT}\|} = \frac{(0, 0, -\sqrt{3}) - (0, 0, 0)}{\sqrt{0^2 + 0^2 + (-\sqrt{3})^2}} = \frac{(0, 0, -\sqrt{3})}{\sqrt{3}} = (0, 0, -1)$$ - $u$ 벡터 (X축 대응)
$$u = \frac{\mathbf{UP} \times n}{\|\mathbf{UP} \times n\|} = \frac{(0, 1, 0) \times (0, 0, -1)}{\|(0, 1, 0) \times (0, 0, -1)\|} = \frac{(-1, 0, 0)}{1} = (-1, 0, 0)$$ - $v$ 벡터 (Y축 대응)
$$v = n \times u = (0, 0, -1) \times (-1, 0, 0) = (0, 1, 0)$$
-
Basis (기저): $u = (-1, 0, 0),\; v = (0, 1, 0),\; n = (0, 0, -1)$
- Origin (원점): $(0, 0, -\sqrt{3})$
- (b) View transform 작성
- 이동 행렬 ($T$)
$$T = \begin{pmatrix} 1 & 0 & 0 & -\mathbf{EYE}_x \\ 0 & 1 & 0 & -\mathbf{EYE}_y \\ 0 & 0 & 1 & -\mathbf{EYE}_z \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & \sqrt{3} \\ 0 & 0 & 0 & 1 \end{pmatrix}$$ - 회전 행렬 ($R$)
$$R = \begin{pmatrix} u_x & u_y & u_z & 0 \\ v_x & v_y & v_z & 0 \\ n_x & n_y & n_z & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} -1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & -1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}$$ - 최종 뷰 변환 행렬 ($M_{view}$)
$$M_{view} = R \cdot T = \begin{pmatrix} -1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & -1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & \sqrt{3} \\ 0 & 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} -1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & -1 & -\sqrt{3} \\ 0 & 0 & 0 & 1 \end{pmatrix}$$
- 이동 행렬 ($T$)
- (a) Camera space의 원점(origin)과 기저(basis)
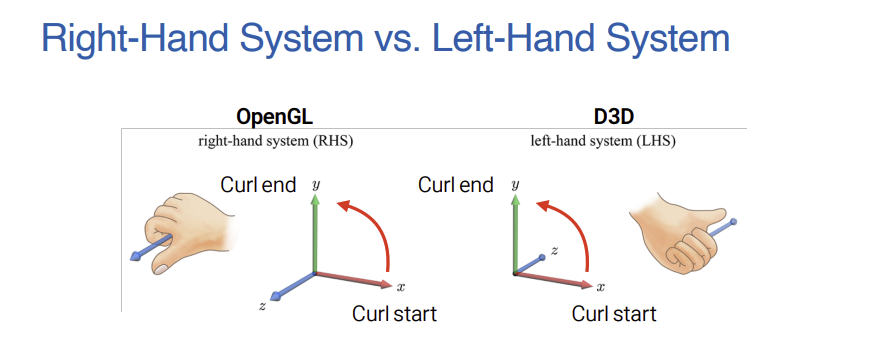
- OpenGL에서 사용하는 오른손 좌표계(RHS)와 Direct3D에서 사용하는 왼손 좌표계(LHS)의 Z축 방향 차이를 손 그림으로 직관적으로 비교한다.
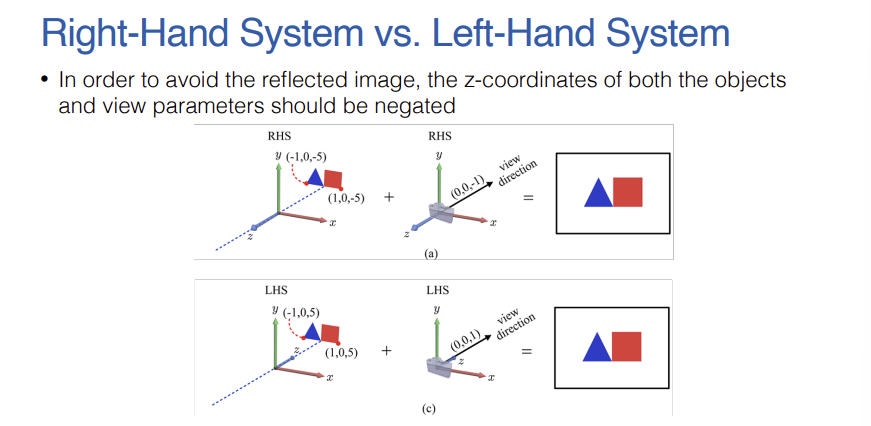
- 이러한 좌표계 차이 때문에 오른손 좌표계(RHS)를 기준으로 만들어진 오브젝트와 카메라 파라미터를 그대로 왼손 좌표계(LHS)로 가져갈 경우 카메라에 맺히는 이미지가 좌우로 반전되어 나타나는 오류가 발생한다.
- 이를 해결하기 위해 물체의 Z좌표와 View 파라미터의 Z좌표 부호를 모두 음수로 뒤집어주면 양쪽 시스템에서 동일한 이미지를 정상적으로 얻을 수 있다.
4. View Frustum 및 Culling & Clipping
아래 슬라이드들은 카메라가 볼 수 있는 영역을 정의하는 View Frustum (절두체)의 개념과 이를 활용한 최적화 기법인 Culling 및 Clipping에 관한 내용을 포함한다.
| 구분 | 대상 | 수행 위치 |
| Culling | Object | CPU |
| Clipping | Polygon | GPU |
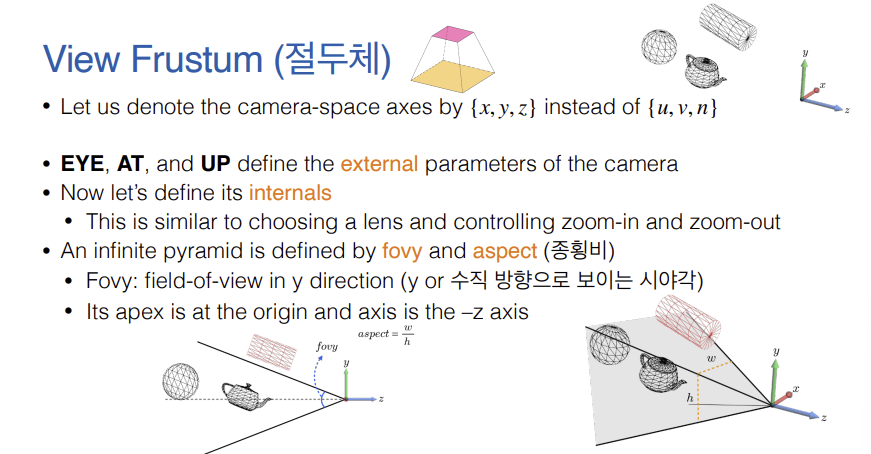
View Frustum (절두체)의 개념은 카메라의 내부 파라미터(Internals)를 정의하여 실제로 '보이는 영역'을 설정하는 과정이다. 네 가지 주요 요소로 구성된다.
- fovy (Field of View in Y): y축(수직) 방향으로의 시야각.
- aspect (종횡비): 화면의 너비(w)와 높이(h)의 비율 ($w/h$).
- near plane
- far plane

- 무한한 피라미드 영역을 현실적으로 제한하기 위해 near plane(근거리 평면, $n$)과 far plane(원거리 평면, $f$)을 도입한다.
- 이 두 평면으로 피라미드의 위아래를 잘라내면 끝이 잘린 피라미드 모양인 절두체(Frustum)가 완성된다. 이 절두체 내부의 물체만이 최종적으로 화면에 렌더링된다.
- 이러한 인위적인 절단면(near/far)은 사람의 눈이나 실제 카메라에는 없지만, 컴퓨터 그래픽스에서 연산의 복잡도를 줄이기 위해 도입된 수학적 편의 장치이다.
** 2024-2 퀴즈 **

- 정답:
- 카메라의 구성요소 (Externals): 카메라는 3D 월드 공간에서 자신의 위치와 바라보는 방향(Pose)을 정의하기 위해 다음 세 가지 핵심 요소를 사용한다.
- EYE: 가상 카메라가 위치한 3D 공간 상의 실제 좌표를 의미한다.
- AT: 카메라가 렌즈의 초점을 맞추고 바라보는 3D 공간의 특정 기준점을 의미한다.
- UP: 카메라의 윗부분(정수리)이 어느 방향을 향하고 있는지 가리키는 상향 벡터 역할을 한다. 보통 월드 공간의 Y축을 사용하게 된다. 이 세 가지 요소를 수학적으로 연산하여 카메라 공간을 이루는 직교 기저 벡터(u, v, n)를 도출하게 된다.
- View Frustum의 구성요소 (Internals): 뷰 프러스텀은 카메라가 공간에서 실제로 식별하고 화면에 렌더링할 수 있는 유효 영역을 정의하는 절두체(끝이 잘린 피라미드) 형태의 공간이며, 다음 네 가지 요소로 구성된다.
- fovy (Field of View in Y): 수직(Y축) 방향으로 확보되는 카메라의 시야각을 의미한다.
- aspect (Aspect Ratio): 카메라가 담아낼 화면의 너비(Width)와 높이(Height)의 비율을 의미한다.
- Near plane ($n$): 카메라와 가장 가까운 렌더링 경계면까지의 거리를 의미하며, 이 평면보다 카메라에 가까운 물체는 시야에서 제외된다.
- Far plane ($f$): 카메라가 볼 수 있는 가장 먼 렌더링 경계면까지의 거리를 의미하며, 이 평면보다 멀리 있는 물체 또한 렌더링 대상에서 제외된다.
- 카메라의 구성요소 (Externals): 카메라는 3D 월드 공간에서 자신의 위치와 바라보는 방향(Pose)을 정의하기 위해 다음 세 가지 핵심 요소를 사용한다.

- Culling은 View Frustum 영역 완전히 바깥에 있는 물체(Object) 전체를 렌더링 대상에서 통째로 제외하는 과정이다. 그릴 필요가 없는 물체를 사전에 제거하여 GPU의 렌더링 속도를 크게 향상시키기 위함이다.
- 단위가 'Object' 수준이며, GPU로 데이터를 보내기 전 단계인 CPU에서 수행된다.
** 2024-2 퀴즈 **

- 정답: View Frustum Culling은 View Frustum 영역 완전히 바깥에 있는 물체(Object) 전체를 렌더링 대상에서 통째로 제외하는 과정이다.
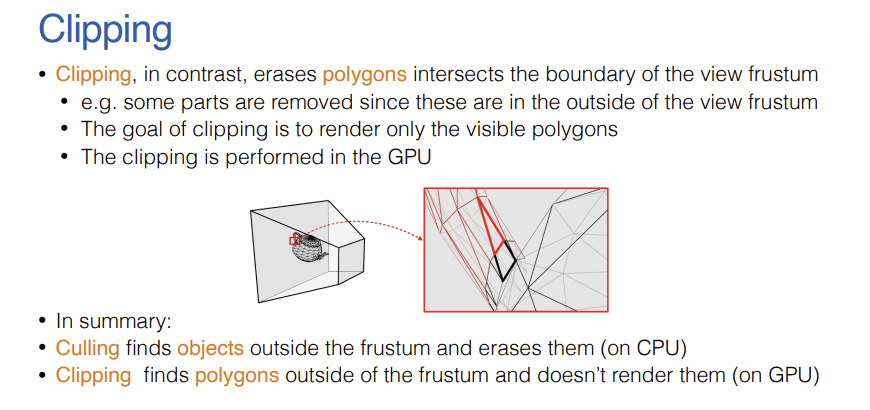
- Clipping은 View Frustum의 경계면에 걸쳐 있는 폴리곤(Polygon)을 잘라내어, Frustum 바깥에 있는 '부분'만을 지우는 과정이다.
- 즉, 정확히 시야에 들어오는 폴리곤만 화면에 렌더링하기 위함이다. 이는 Object가 아닌 'Polygon' 단위의 정밀한 연산이며, 렌더링 파이프라인 후반부인 GPU에서 수행된다.

- 피라미드 형태(절두체)의 경계면과 수많은 폴리곤 간의 교차 여부를 일일이 계산(클리핑)하는 것은 수학적으로 매우 복잡하고 비효율적이다.
- 따라서 그래픽스 파이프라인에서는 절두체 형태의 프러스텀을 그대로 사용하여 Clipping하지 않으며, 연산을 단순화하기 위해 Frustum의 형태를 직육면체(정규화된 장치 좌표계, NDC)로 변형(Deform)시킨 후 Clipping을 수행하게 된다. 이 과정이 다음 단계인 '투영 변환(Projection Transform)'의 핵심 목적이다.
5. Projection Transform

- Projection Transform은 이전 단계의 피라미드 형태인 View Frustum (절두체)을 원점을 중심으로 하는 가로, 세로, 깊이가 각각 2인 정육면체($-1 \le x, y, z \le 1$) 형태로 찌그러뜨려 변형하는 과정이다.
- Frustum 내부의 모든 Camera Space 물체도 이 변형에 맞춰 함께 변형되며, 이 정육면체 영역을 벗어나는 Polygon들은 잘려나가는 클리핑(Clipping) 처리가 수행된다. 이렇게 projection transform이 완료되어 정육면체 형태로 규격화된 상태의 공간을 클립 공간(Clip Space)이라고 명명한다.
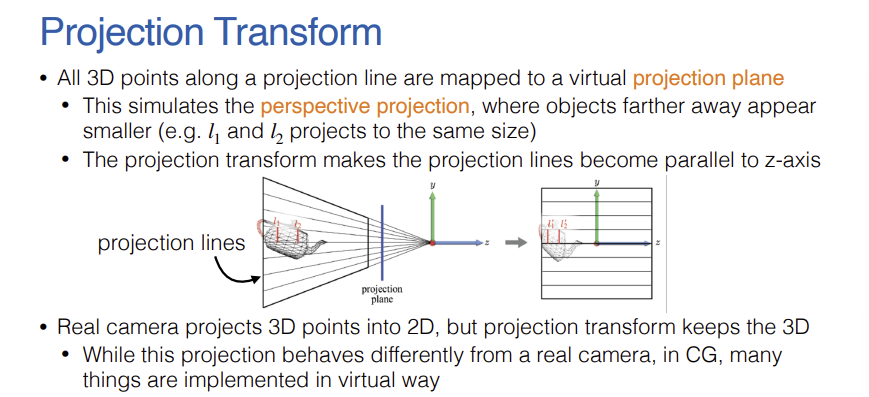
- 이 변환 과정은 멀리 있는 물체가 더 작게 보이는 원근감을 수학적으로 구현한다. 기하학적으로 보면 한 점(카메라 원점)으로 모이던 방사형의 투영 선(Projection lines)들을 Z축과 완벽히 평행한 직선 형태로 쭉 펴주는 조작이 이루어진다.
- 그 결과 물리적으로 더 큰 물체인 $l_2$가 멀리 떨어져 있을 때, 더 가까이 있는 작은 물체 $l_1$과 동일한 크기로 투영 평면에 맺히게 된다. 실제 카메라는 3D 공간을 2D 평면으로 완전히 납작하게 투영하지만, 컴퓨터 그래픽스에서는 물체의 앞뒤 가림(Depth) 판별을 위해 Z축 깊이 정보를 버리지 않고 3D 상태를 그대로 유지하게 된다.

- 투영 변환을 마친 물체들은 화면에 픽셀 형태로 그려지기 위해 Rasterizer 단계로 넘어가게 된다. 여기서 주의해야 할 점은 Rasterizer가 사용하는 Clip Space은 하드웨어 특성상 왼손 좌표계(LHS)를 기반으로 작동한다는 사실이다.
- 따라서 기존 Camera Space에서 쓰던 오른손 좌표계(RHS)를 왼손 좌표계에 맞추기 위해, 물체들의 Z축 방향 부호를 반대로 뒤집어주는 Z-negation 연산이 행렬 내부에 수식으로 반영되어 계산된다.
Summary
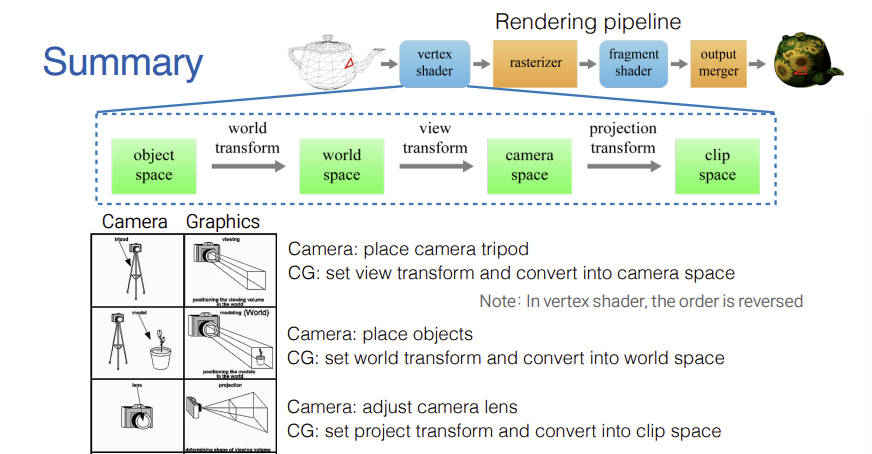
Graphics Pipeline 중 Vertex Shader 단계에서 주로 이어지는 핵심 변환은 3단계로 구성된다. 따라서 물체의 정점 (Vertex, $v$)에 월드($W$), 뷰($V$), 투영($P$) 행렬을 순서대로 적용할 때 수식은 $P \cdot V \cdot W \cdot v$ 가 된다. 즉, 행렬 곱셈은 오른쪽에서 왼쪽 방향으로 계산되므로 개념적인 적용 순서와 수식상의 곱셈 순서가 반대가 됨을 명시한 것이다.
1. World Transform
- 각 객체마의 독립적인 Object Space를 하나의 통합된 전체 공간인 World Space로 변환한다. 이를 통해 여러 물체들이 한 공간 안에서 서로 상호작용할 수 있게 된다.
2. View Transform
- World Space의 모든 물체들을 카메라의 시점 (EYE)과 방향 (AT, UP)을 기준으로 재배치하여 Camera Space으로 변환한다. 이를 위해 카메라의 기저 벡터 $u, v, n$을 계산하고 $RT$ 행렬을 적용한다.
3. Projection Transform
- 시야각 (fovy), 종횡비 (aspect), near plane, far plane으로 정의된 View Frustum 영역을 정육면체 형태의 Clip Space으로 찌그러뜨려 변환한다. 이 과정에서 원근감이 적용되며, 화면 밖으로 벗어난 부분은 Clipping되어 잘려나간다.

'4. University Study > Multimedia' 카테고리의 다른 글
| [Multimedia] Lecture 9. Lighting (0) | 2026.04.04 |
|---|---|
| [Multimedia] Lecture 8. Texturing (0) | 2026.04.03 |
| [Multimedia] Lecture 7. Rasterizer, Fragment Shader, Output Merger (0) | 2026.03.28 |
| [Multimedia] Lecture 4. Geometric Transformations (1) | 2026.03.15 |
| [Multimedia] Lecture 2. Modeling (0) | 2026.03.14 |



