

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- C++
- Linear Regression
- overfiting
- do it! 알고리즘 코딩테스트: c++편
- numpy
- CBOW
- classification
- model selection
- jini impurity
- 딥러닝
- deep learning
- marchine learning
- tree purning
- 밑바닥부터 시작하는 딥러닝2
- 고전소설
- Baekjoon
- BFS
- RNN
- underfiting
- marchien learning
- 밑바닥부터 시작하는 딥러닝
- Language model
- quadratic discriminant analysis
- dynamic programming
- Machine Learning
- Backtracking
- DFS
- Python
- SQLD
- word2vec
- Today
- Total
newhaneul
[밑바닥부터 시작하는 딥러닝2: Chapter 2] 자연어와 단어의 분산 표현 본문
[밑바닥부터 시작하는 딥러닝2: Chapter 2] 자연어와 단어의 분산 표현
뉴하늘 2024. 11. 28. 16:03
본 포스팅은 밑바닥부터 시작하는 딥러닝2을 토대로 공부한 내용을 정리하기 위한 포스팅입니다.
해당 도서에 나오는 Source Code 및 자료는 GitHub를 참조하여 진행하였습니다.
https://github.com/WegraLee/deep-learning-from-scratch-2
자연어 처리(National Language Processing, NLP)는 ’사람이 쓰는 언어를 컴퓨터에게 이해시키기는 기술‘을 말한다. 사람이 쓰는 말은 ‘문자’로 구성되며, 말의 의미는 ‘단어’로 구성된다. 즉, 단어는 의미의 최소 단위이다. 그래서 컴퓨터에게 먼저 ‘단어의 의미’를 이해시키는 것이 자연어 처리의 시작이라고 볼 수 있다. 이 책에서는 세 가지 기법으로 ‘단어’를 이해시킨다.
- 시소러스를 활용한 기법
- 통계 기반 기법
- 추론 기반 기법(word2vec)
2.2 시소러스
자연어 처리의 역사를 보면 단어의 의미를 <표준국어대사전>같이 사람이 이용하는 일반적인 사전이 아니라 시소러스 형태의 사전을 애용해왔다. 시소러스란 유의어 사전으로, ‘뜻이 같은 동의어‘나 ’뜻이 비슷한 유의어’가 한 그룹으로 분류되어 있는데, 자연어 처리에 사용되는 시소러스의 경우에는 단어 사이의 ‘상위와 하위’ 혹은 ‘전체와 부분’ 등, 세세한 관계까지 [그림 2-2]의 예처럼 그래프 구조로 정의한다.

이처럼 모든 단어에 대한 유의어 집합을 만든 다음, 단어들의 관계를 그래프로 표현하여 단어 사이의 연결을 정의할 수 있을 것이다.
보통 자연어 처리 분야에서 가장 유명한 시소러스는 WordNet이다. WordNet을 사용하면 유의어를 얻거나 ‘단어 네트워크’를 이용할 수 있다. 하지만 WordNet과 같은 시소러스는 크나큰 결점이 존재한다.
- 시대 변화에 대응하기 어렵다.
- 시소러스를 만드는 데 엄청난 인적 비용이 발생한다.
- 단어의 미묘한 차이를 표현할 수 없다. (ex. 용법이 다른 경우)
이 문제를 피하기 위해, ‘통계 기반 기법’과 신경망을 사용한 ‘추론 기반 기법’을 사용한다.
2.3 통계 기반 기법
통계 기반 기법에서는 말뭉치(corpus)를 이용한다. 통계 기반 기법의 목표는 사람의 지식으로 가득한 말뭉치에서 자동으로, 그리고 효율적으로 그 핵심을 추출하는 것이다.
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split('')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
preprocess 함수는 말뭉치를 입력받고 전처리하는 함수이다. 말뭉치를 단어 조각으로 분리한 후 딕셔너리를 통해 단어 ID 목록과 단어 목록을 만든다. 그 후 말뭉치를 단어 ID로 변환한 다음, 넘파이 배열로 변환한다.
2.3.2 단어의 분산 표현
‘단어의 의미’를 정확하게 파악할 수 있는 방법은 벡터로 변환하는 것이다. RGB의 세 가지 성분이 어떤 비율로 섞여 있는지를 표현하기 위해 벡터로 표현하는 것과 같은 이치이다. 이를 자연어 처리 분야에서는 단어의 분산 표현(distrbutional representation)이라고 한다.
단어를 벡터로 표현하는 아이디어는 바로 ‘단어의 의미는 주변 단어에 의해 형성된다’라는 것이다. 이를 분포 가설(distributional hypothesis)이라 하며, 단어를 벡터로 표현하는 연구들 대부분이 이 가설에 기초한다. 분포 가설은 단어 자체에는 의미가 없고, 그 단어가 사용된 ’맥락‘이 의미를 형성한다는 것이다. 예컨대 [그림 2-3]은 좌우의 각 두 단어씩이 ’맥락‘에 해당한다.

[그림 2-3]처럼 ‘맥락’이란 특정 단어를 중심에 둔 그 주변 단어를 말하고, 맥락의 크기를 ‘윈도우 크기(window size)'라고 한다.
2.3.4 동시발생 행렬
문장 'You say goodbye and i say hello .'에서 window size가 1일때 'say'의 맥락에 포함되는 단어는 [그림 2-6]과 같은 벡터로 표현할 수 있다.

이 작업을 모든 단어에 대해서 수행한 결과는 [그림 2-7]과 같고, 이 표의 각 행은 해당 단어를 표현한 벡터가 된다.
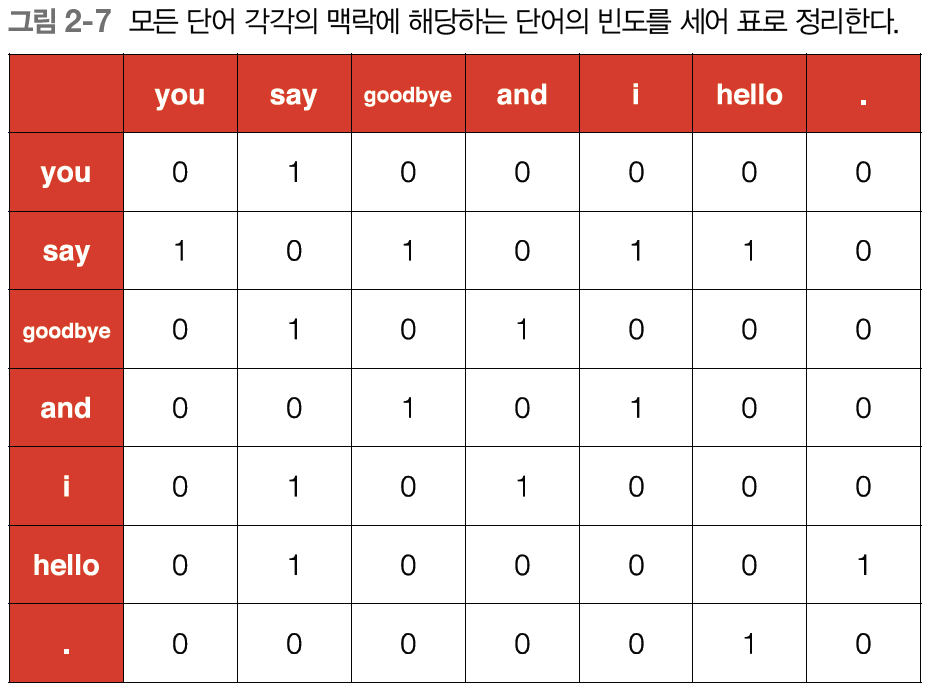
이 표가 행렬의 형태를 띤다는 뜻에서 동시발생 행렬(co-occurrence matrix)라고 한다. [그림 2-7]의 동시발생 행렬을 활용하면 단어를 벡터로 나타낼 수 있다. 그러면 말뭉치로부터 동시발생 행렬을 만들어주는 함수를 파이썬으로 구현해보도록 한다.
def create_co_matrix(corpus, vocab_size, window_size = 1):
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size, vocab_size), dtype = np.int 32)
for idx, word_id in enumerate(corpus):
for i in range(1, window_size + 1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id, left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id, right_word_id] += 1
return co_matrix
말뭉치의 왼쪽 끝과 오른쪽 끝 경계를 벗어나지 않는지 확인하면서 자동으로 동시발생 행렬을 만들어준다.
2.3.5 벡터 간 유사도
벡터 사이의 유사도를 측정하는 방법은 다양하지만, 단어 벡터의 유사도를 나타낼 때는 코사인 유사도(cosine similarity)를 자주 이용한다. 코사인 유사도는 다음 식으로 정의된다.

[식 2.1]의 핵심은 벡터를 정규화하고 내적을 구하는 것이다. cosine similarity의 분모는 각 벡터의 norm(벡터의 크기)이 등장한다. cosine similarity를 python으로 구현하면 다음과 같다.
def cos_similarity(x, y, eps = 1e-8):
nx = x / (np.sqrt(np.sum(x**2)) + eps)
ny = y / (np.sqrt(np.sum(y**2)) + eps)
return np.dot(nx, ny)
cosine similarity 함수를 구현했으니 이번엔 어떤 단어가 검색어로 주어지면, 그 검색어와 비슷한 단어를 유사도 순으로 출력하는 함수를 구현해보도록 한다.
def most_similar(query, word_to_id, id_to_word, word_matrix, top = 5):
count = 0
# 1. 검색어를 꺼낸다.
if query not in word_to_id:
return
print('\n[query] ' + query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
# 2. cosine similarity 계산
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i], query_vec)
# 3. cosine similarity 계산 결과를 기준으로 내림차순 출력
for i in (-1 * similarity).argsort():
if id_to_word[i] == query:
continue
print(' %s: %s' %(id_to_word[i], similarity[i]))
count += 1
if count >= top:
return
이 코드는 다음 순서로 동작한다.
1. 검색어의 단어 벡터를 꺼낸다.
2. 검색어의 단어 벡터와 다른 모든 단어 벡터와의 코사인 유도를 각각 구한다.
3. 계산한 코사인 유사도 결과를 기준으로 값이 높은 순서대로 출력한다.
+ argsort() 메서드는 넘파이 배열의 원소를 오름차순으로 정렬한다.(단, 반환값은 배열의 인덱스이다).
x = np.array([100, -20, 2])
print(x)
print(x.argsort())
print((-1 * x).argsort())
즉, argsort()의 결과는 인덱스가 1인 원소(-20), 2인 원소(2), 0인 원소(100) 순으로 정렬된 것이다. 따라서 넘파이 배열의 각 원소에 마이너스를 곱한 후 argsort() 메서드를 호출하면 내림차순으로 결과를 얻을 수 있는 것이다.
그럼 ‘you'를 검색어로 지정해 유사한 단어들을 출력해보도록 한다.
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
most_similar('you', word_to_id, id_to_word, C, top = 5)
이 결과는 검색어 ‘you'와 유사한 단어를 상위 5개만 출력한 것이다. 결과를 보면 ’i‘와 'you' 모두 인칭대명사이므로 둘이 비슷하다는 건 납득이 되지만, ’goodbye'와 ’hello'의 코사인 유사도가 높다는 것은 일반적인 직관과는 거리가 멀다. 지금은 말뭉치의 크기가 너무 작다는 것이 원인이다. 나중에 더 큰 말뭉치를 사용하여 결과를 확인해보도록 한다.
2.4 통계 기반 기법 개선하기
이번 절에서는 동시발생 행렬의 개선 작업을 진행하도록 한다. 앞 절에서 본 동시발생 행렬의 원소는 두 단어가 동시에 발생한 횟수를 나타낸다. 그러나 고빈도 단어(많이 출현하는 단어)로 코드를 돌려보면 ‘발생’ 횟수라는 것은 안좋은 특징이라는 것을 알 수 있다. 예로 들어 'the'와 ’car'의 동시발생을 생각해보자. 'car'는 ‘drive'와 관련이 깊지만 ’the car‘가 더 자주 보일 것이다. 이처럼 단순히 등장 횟수만을 본다면 ’car‘는 'drive'보다는 'the’와의 관련성이 훨씬 강하다고 나오게 되고, 이는 ‘the’가 고빈도 단어라서 'car'와 강한 관련성을 갖는다고 평가되기 때문이다.
이 문제를 해결하기 위해 점별 상호정보량(Pointwise Mutual Information, PMI)이라는 척도를 사용한다. PMI는 확률 변수 x와 y에 대해 다음 식으로 정의된다.

[식 2.2]에서 P(x)는 x가 일어날 확률, P(y)는 y가 일어날 확률, P(x, y)는 x와 y가 동시에 일어날 확률을 뜻한다. 이 PMI 값이 높을수록 관련성이 높다는 의미이다. 그럼 동시발생 행렬을 사용하여 [식 2.2]를 변환해보도록 한다. C는 동시발생 행렬, C(x, y)는 단어 x와 y가 동시발생하는 횟수, C(x)와 C(y)는 각각 단어 x와 y의 등장 횟수이다.

그럼 [식 2.3]을 토대로 말뭉치의 단어 수(N)이 10,000이라 하고, 'the‘, ‘car', ’drive’가 각각 1,000번, 20번, 10번 등장했다고 하자. 그리고 ‘the’와 ‘car'의 동시발생 수는 10회, ’car'와 ‘drive'의 동시발생 수는 5회라고 가정한다. 이 조건으로 계산한 PMI 결과는 다음과 같다.


PMI 결과를 보니 ‘car’는 'drive‘와 관련성이 강하다는것을 확인할 수 있다. 하지만 PMI에도 주의할 점이 존재한다. 만약 두 단어의 동시발생 횟수가 0이면 log의 지수가 0이 되고, 이는 -∞이 된다. 이 문제를 피하기 위해 실제로 구현할 때는 양의 상호정보량(Postive PMI, PPMI)을 사용한다.

이 식에 따라 PMI가 음수일 때는 0으로 취급한다. 그럼 동시발생 행렬을 PPMI 행렬로 변환하는 함수를 구현하도록 한다.
def ppmi(C, verbose = False, eps = 1e-8):
M = np.zeros_like(C, dtype = np.float32)
N = np.sum(C)
S = np.sum(C, axis = 0)
total = C.shape[0] * C.shape[1]
cnt = 0
for i in range(C.shape[0]):
for j in range(C.shape[1]):
pmi = np.log2(C[i, j] * N / (S[j]*S[i]) + eps)
M[i, j] = max(0, pmi)
if verbose:
cnt += 1
if cnt % (total // 100 + 1) == 0:
print('%.1f%% 완료' % (100 * cnt / total))
return M 이 코드는 동시발생 행렬에 대해서만 PPMI 행렬을 구할 수 있도록 하고자 단순화 해 구현했다. 또한 log가 음의 무한대가 되는 사태를 피하기 위해 eps라는 작은 값을 사용했다.
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
W = ppmi(C)
print('동시발생 행렬')
print(C)
print('-' * 50)
print('PPMI')
print(W)
이것으로 동시발생 행렬을 PPMI 행렬로 변환하는 법을 알아보았다. 그러나 PPMI 행렬에도 여전히 2가지의 큰 문제가 존재한다.
1. 말뭉치의 어휘 수가 증가함에 따라 각 단어 벡터의 차원 수도 증가한다는 문제가 있다.
2. PPMI 행렬의 내용을 들여다보면 원소 대부분이 0인 것을 알 수 있다. 이는 각 원소의 ‘중요도’가 낮다는 것을 의미하며, 이런 벡터는 노이즈에 약하고 견고하지 못하다는 약점을 가진다.
이 문제에 대처하고자 자주 수행하는 기법으로 벡터의 차원 감소가 있다.
2.4.2 차원 감소
차원 감소(dimensionality reduction)은 ‘중요한 정보’는 최대한 유지하면서 벡터의 차원을 줄이는 방법을 말한다. [그림 2-8]처럼 데이터의 분포를 고려해 중요한 ‘축’을 찾는 일을 수행한다.

여기서 중요한 것은 가장 적합한 축을 찾아내는 일로, 1차원 값만으로도 데이터의 본질적인 차이를 구별할 수 있어야 한다. 차원을 감소시키는 방법은 여러 가지가 있지만, 여기서는 특잇값분해(Singular Value Decomposition, SVD)를 이용한다. SVD는 임의의 행렬을 세 행렬의 곱으로 분해하며, 수식으로는 다음과 같다.

[식 2.7]에서 U와 V는 직교행렬(orthogonal matrix)이고, 그 열벡터는 서로 직교한다. 또한 S는 대각행렬(diagonal matrix)이다. 이 수식을 시각적으로 표현한 값은 [그림 2-9]와 같다.

직교행렬 U는 어떠한 공간의 축(기저)을 형성한다. 지금의 맥락으로 이 U 행렬은 ‘단어 공간’으로 취급할 수 있다. 또한 S는 대각 행렬로, 그 대각성분에는 ‘특잇값’이 큰 순서로 나열되어 있다. 특잇값이란, ‘해당 축’의 중요도라고 간주할 수 있다. 그래서 [그림 2-10]과 같이 중요도가 낮은 원소(특잇값이 작은 원소)를 깎아내는 방법을 생각할 수 있다.

행렬 S에서 특잇값이 작다면 중요도가 낮다는 뜻이므로, 행렬 U에서 여분의 열벡터를 깎아내어 원래의 행렬을 근사할 수 있다. 그러면 행렬 X의 각 행에는 해당 단어 ID의 단어 벡터가 저장되어 있으며, 그 단어 벡터가 행렬 U'라는 차원 감소된 벡터로 표현되는 것이다.
이제 SVD를 파이썬 코드로 살펴보도록 한다. SVD는 넘파이의 linalg 모듈이 제공하는 svd 메서드로 실행할 수 있다. 여기서 linalg은 선형대수(linear algebra)의 약어이다. 그럼, 동시발생 행렬을 만들어 PPMI 행렬로 변환한 다음 SVD를 적용해보자.
import matplotlib.pyplot as plt
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
C = create_co_matrix(corpus, vocab_size)
W = ppmi(C)
#SVD
U, S, V = np.linalg.svd(W)
for word, word_id in word_to_id.items():
plt.annotate(word, (U[word_id, 0], U[word_id, 1]))
plt.scatter(U[:, 0], U[:, 1], alpha = 0.5)
plt.show()
SVD에 의해 변환된 밀집벡터 표현은 변수 U에 저장된다. 코드를 실행해보면 [그림 2-11]과 같은 결과를 얻을 수 있다.

지금까지 사용한 말뭉치는 아주 작아서 결과라고 부르기가 어렵다. 그래서 이번엔 PTB 데이터셋이라는 더 큰 말뭉치를 사용하여 똑같은 실험을 진행해보도록 한다.
2.4.4 PTB 데이터셋
펜 트리뱅크(Penn Treebank, PTB) 말뭉치는 word2vec의 발명자인 토마스 미콜로프의 웹 페이지에서 받을 수 있다. 이 PTB 말뭉치는 텍스트 파일로 제공되며, 원래의 PTB 문장에 몇 가지 전처리를 해두었다(희소 단어는 <unk>로, 구체적인 숫자는 ‘N'으로 대체하는 등). PTB 말뭉치의 내용은 아래와 같다.

이 책에서는 PTB 데이터셋을 쉽게 이용할 수 있도록 전용 파이썬 코드를 제공한다. github에서 제공하는 ptb.py를 사용해 PTB 데이터셋에 통계 기반 기법을 적용해보도록 한다. 이번에는 큰 행렬에 SVD를 적용해야 하므로 고속 SVD를 이용하는 것이 좋다. 고속 SVD를 이용하려면 sklearn 모듈을 설치해야 한다. 소스 코드는 아래와 같다.
import ptb
window_size = 2
wordvec_size = 100
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
print('동시발생 수 계산 ...')
C = create_co_matrix(corpus, vocab_size, window_size)
print('PPMI 계산 ...')
W = ppmi(C, verbose=True)
print('calculating SVD ...')
try:
# truncated SVD (빠르다!)
from sklearn.utils.extmath import randomized_svd
U, S, V = randomized_svd(W, n_components=wordvec_size, n_iter=5,
random_state=None)
except ImportError:
# SVD (느리다)
U, S, V = np.linalg.svd(W)
word_vecs = U[:, :wordvec_size]
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)2.5 정리
시소러스 기반 기법에서는 단어들의 관련성을 사람이 수작업으로 하나씩 정의해야한다. 이 작업은 매우 힘들고 표현력에도 한계가 있다.
통계 기반 기법은 말뭉치로부터 단어의 의미를 자동으로 추출하고, 그 의미를 벡터로 표현한다. 구체적으로는 단어의 동시발생 행렬을 만들고, PPMI 행렬로 변환한 다음, 안전성을 높이기 위해 SVD를 이용해 차원을 감소시켜 각 단어의 분산 표현을 만들어낸다.
'2. Artificial Intelligence > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝2: Chapter 4] word2vec 속도 개선 (2) | 2025.01.02 |
|---|---|
| [밑바닥부터 시작하는 딥러닝2: Chapter 3] word2vec (0) | 2024.12.07 |
| [밑바닥부터 시작하는 딥러닝1: Chapter 8] 딥러닝 (4) | 2024.09.27 |
| [밑바닥부터 시작하는 딥러닝1: Chapter 7] 합성곱 신경망(CNN) (2) | 2024.09.24 |
| [밑바닥부터 시작하는 딥러닝1: Chapter 6] 학습 관련 기술들 (3) | 2024.09.19 |



