| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Positional Encoding
- BFS
- Baekjoon
- computer vision
- SQLD
- C++
- dropout
- marchine learning
- 딥러닝
- mask r-cnn
- CNN
- Alexnet
- DFS
- assignment1
- Transformer
- RNN
- Machine Learning
- 밑바닥부터 시작하는 딥러닝2
- Multi-Head Attention
- cs231n
- deep learning
- CPP
- do it! 알고리즘 코딩테스트: c++편
- Regularization
- assignment2
- 밑바닥부터 시작하는 딥러닝
- Algorithm
- Optimization
- Python
- Adam
- Today
- Total
newhaneul
[Stanford Univ: CS231n] Lecture 6. Training Neural Networks Part 1 본문
[Stanford Univ: CS231n] Lecture 6. Training Neural Networks Part 1
뉴하늘 2025. 4. 22. 18:49본 포스팅은 Stanford University School of Engineering의 CS231n: Convolutional Neural Networks for Visual Recognition을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
https://youtu.be/wEoyxE0GP2M?si=2UO9KpMIuSfOycP9
https://github.com/cs231n/cs231n.github.io
GitHub - cs231n/cs231n.github.io: Public facing notes page
Public facing notes page. Contribute to cs231n/cs231n.github.io development by creating an account on GitHub.
github.com
1. Activation Functions
Activation Function(활성화 함수)은 인공 신경망에서 뉴런이 출력할 값을 결정하는 비선형 함수로, 전체 신경망이 복잡한 비선형 패턴을 학습할 수 있도록 도와주는 핵심 구성 요소가 된다.
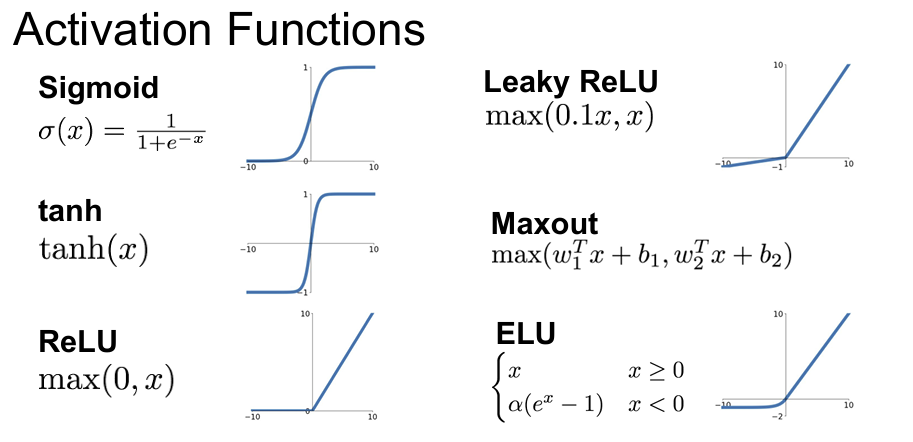
Sigmoid
Sigmoid Function은 Vanishing Gradient Problem, Zero-centered 문제점이 존재한다. Sigmoid 함수는 입력 값이 매우 크거나 작을 경우, 미분 값이 0에 가까워져 역전파 시 가중치 업데이트가 거의 이루어지지 않는다. 즉, Vanishing Gradient Problem이 존재한다.

Sigmoid의 출력은 항상(0, 1) 범위에 있으므로, Sigmoid의 미분 값은 항상 양수가 나오게 된다.
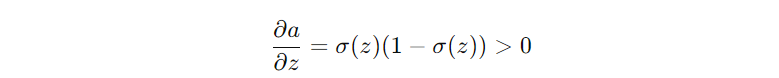
이때 Chain rule을 적용하게 되면 아래와 같다. 따라서 Loss에 대한 W의 기울기는 x의 부호에 따라 바뀌게 됨을 알 수 있다. 즉, Gradient의 방향을 바꾸는 핵심은 입력 x의 부호이다.

그렇기 때문에 x가 양수이면 gradient도 양수이고, x가 음수이면 gradient도 음수여서 zig zag 형태로 W가 업데이트 된다. 이는 학습 경로가 비효율적이게 되고 수렴 속도가 느려지는 문제가 있다.

Tanh
Tanh Function은 Sigmoid의 zero-centered 문제를 해결하였지만 여전히 큰 입력에서 gradient가 0에 수렴하는 Vanishing Gradient Problem이 존재한다.

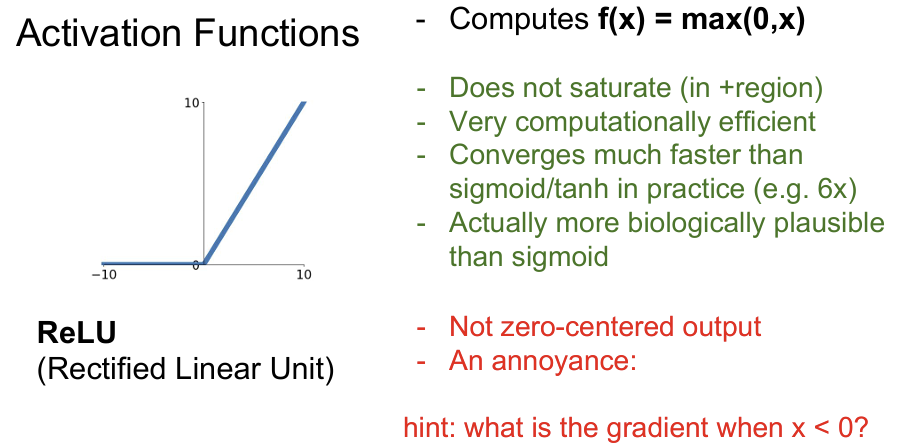
ReLU
ReLU Function은 Vanishing Gradient problem이 덜하고, 계산이 간단하고 빠르다는 장점이 있다. 하지만 zero-centered가 아니고 input x가 0 이하인 경우 gradient가 0이 되어 학습이 진행되지 않는 문제가 존재한다.

Leaky ReLU
Leaky ReLU는 ReLU의 단점을 보완하여 음수 입력에도 작은 기울기를 남기는 함수이다. 덕분에 ReLU의 대부분 문제들을 해결하였다.

ELU
ELU는 Leaky ReLU와 비교하면 음의 영역에서 noise에 더 robust하다는 장점이 있다. 하지만 exponential 연산을 진행하기 때문에 계산이 조금 복잡하다는 단점이 있다.

Maxout Neuron
Maxout Neuron은 2013년에 제안된 활성화 함수로, 기존의 ReLU나 tanh와 같은 고정된 수식 기반의 비선형 함수와는 달리, 학습 가능한 방식으로 비선형성을 생성하는 방식이 특징이다. ReLU와 Leaky ReLU를 일반화한 형태이며, 특히 dropout과 잘 호환되도록 설계되었다.
단점으로는 parameter의 수가 증가하게 되고, 계산량이 많아지게 된다.

2. Data Preprocessing
Machine learning에서는 PCA나 whitening 같은 더 복잡한 전처리 과정도 있긴 하지만 이미지에서는 단순히 zero-mean 정도만 사용하고 normalization 그 밖의 여러 복잡한 방법들은 잘 사용하지 않는다. 일반적으로는 이미지를 다룰 때는 굳이 입력을 더 낮은 차원으로 projection 시키지 않는다. CNN에서는 원본 이미지 자체의 spatial 정보를 이용해서 이미지의 spatial structure를 얻을 수 있도록 한다.
전통적인 머신러닝(SVM, KNN 등)에서는 이미지 데이터를 바로 학습하기 어려워서, 고차원 입력을 PCA(Principal Component Analysis) 같은 방법으로 차원 축소하거나 Whitening을 통해 변수 간 상관성을 제거하고, 분산을 같게 만드는 등의 복잡한 전처리를 자주 사용했다.
하지만 CNN과 같은 딥러닝 모델은 이미지의 공간 구조(spatial structure)를 스스로 추출할 수 있는 능력을 가지고 있다. 그리고 이미지의 경우 이러한 공간 구조(spatial structure)가 중요하기 때문에 입력 이미지의 구조를 손상시키지 않고 그대로 유지하기 위해 굳이 차원 축소를하거나 변수 간 상관성을 제거하지 않는다.
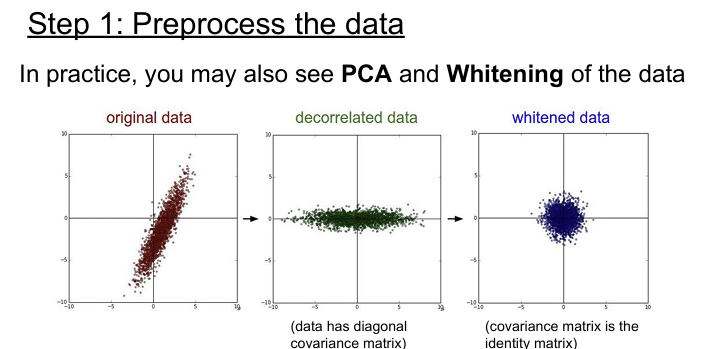
이미지를 다룰때는 기본적으로 zero-mean 으로 전처리를 진행한다. 평균 값은 전체 Training data에서 계산한다. 네트워크에 들어가기 전에 평균값을 빼주게 되고, Test 할 때도 Test Image에 Train 때 계산한 평균 값을 빼준다. 일부 네트워크는 채널 전체의 평균을 구하지 않고 채널마다 평균을 독립적으로 계산하는 경우도 있다. 채널별로 평균이 비슷할 것인지 아니면 독립적으로 계산해야 할 것인지는 판단하기 나름이다.
AlexNet은 Train set의 전체 평균 이미지를 추출하여 전체 Train 이미지들의 픽셀 위치별 평균값을 저장한 이미지(3 x 227 x 227)를 각 이미지에 빼주었다. 공간 정보(위치별 차이)를 고려하여 위치에 따라 빼준 것이다. 이는 데이터의 중심을 0으로 이동하여 학습 안정성을 증가시킨다.
VGGNet은 채널별로 고정된 평균 RGB 값(3개의 값)을 사용한다. Train 이미지 전체에서 R채널의 평균값, G채널의 평균값, B채널의 평균값을 각각 계산하고 입력 이미지의 모든 픽셀에서 해당 채널의 평균값을 빼준다. 즉, 공간 위치는 고려하지 않는다.

3. Weight Initalization
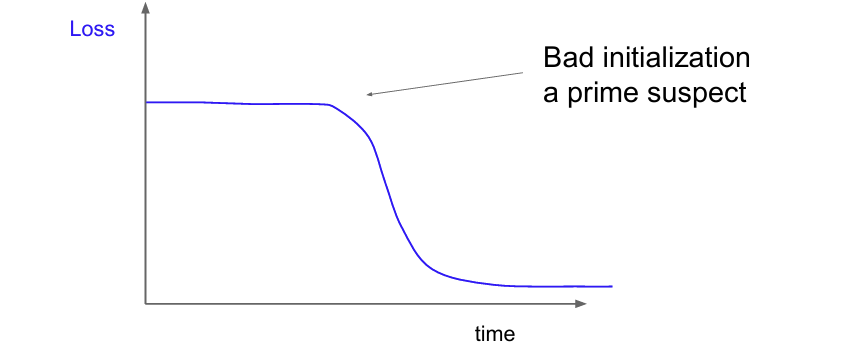
Weight Initialization(가중치 초기화)은 딥러닝 모델에서 각 뉴런의 가중치를 학습 시작 전에 어떤 값으로 설정할지를 결정하는 과정을 말한다. 적절한 초기화를 하지 않으면 Vanishing Gradeint, Exploding Gradient 등의 문제가 발생할 수 있다.
activation function으로 Tanh를 사용했을 때를 보면, Tanh는 출력이 -1 ~ 1 사이이고, 입력이 크거나 작아지면 gradient가 매우 작아지는 vanishing gradient 문제가 발생하기 때문에 Weight Initalization이 중요한 함수이다.
Small Gaussian Initialization
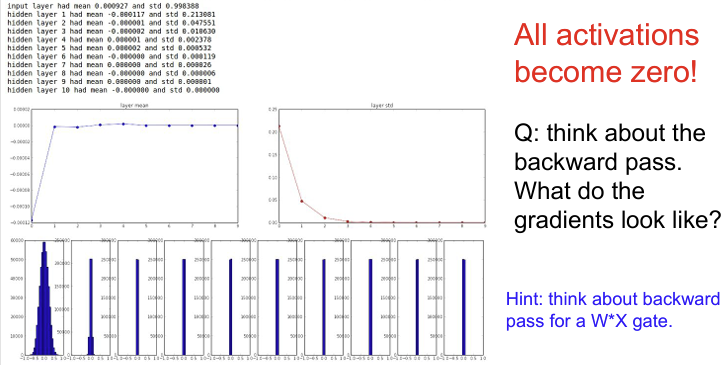
만약 Weight를 임의의 작은 값으로 초기화 시키고 데이터를 forward pass시켜보면 아래와 같은 activation 수치를 얻을 수 있다. 우선 첫번째 layer를 보면 평균은 항상 0 근처에 있다.(tanh 특성상) X와 W를 내적한 값에 tanh를 취하므로 평균은 0에 가까워진다.(zero-centered 이므로)
하지만 표준편차를 보게되면 값이 가파르게 줄어들어서 0에 수렴하는것을 볼 수 있다. 이는 Backpropagation에서 가중치를 업데이트하려면 upstream gradient에 local gradient를 곱해주어야 한다. 이때 local gradient는 x가 곱해져있는 형태가 되는데, 여기서 x는 엄청 작은 값이기 때문에 gradient도 작아지게 되는 것이다. 결국 가중치 데이트가 잘 일어나지 않게 된다.
Big Gaussian Initalization
만약 가중치를 큰 값으로 초기화하면 어떻게 되는지 생각해보자. 큰 가중치를 통과한 출력 tanh(WX)는 1과 -1의 값만을 가지게 될 것이다. 그리고 이때의 gradient는 0에 가까워진다. 즉, 가중치가 큰 값을 가지므로 tanh의 출력은 항상 saturation된다.

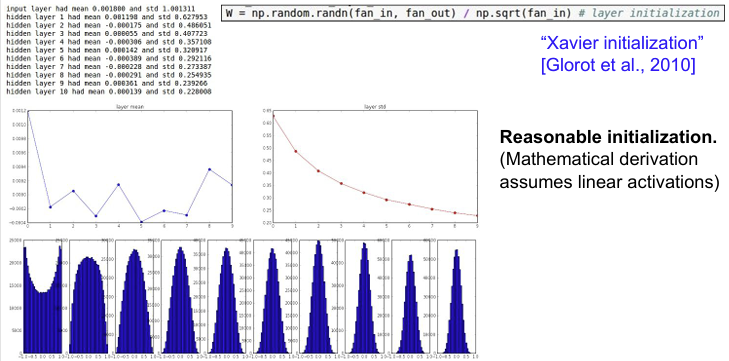
Tanh 함수에서는 위 두가지 문제를 모두 피하기 위해 Xaiver Initalization을 사용한다. 입력과 출력의 노드 수를 고려하여 적절한 분산을 갖도록 조절하는 것이다. 기본적으로 Xavier initialization가 하는 일은 입/출력의 분산을 맞춰주는 것이다. 그리고 이 수식을 통해서 직관적으로 이해할 수 있는 것은 입력의 수가 작으면 더 작은 값으로 나누고 좀 더 큰 값을 얻는다는 점이다. 또한 더 큰 가중치가 필요하다. 왜냐하면 작은 입력의 수가 가중치와 곱해지기 때문에, 가중치가 더 커야만 출력의 분산만큼 큰 값을 얻을 수 있기 때문이다. 반대로 입력의 수가 많은 경우에는 더 작은 가중치가 필요하다.
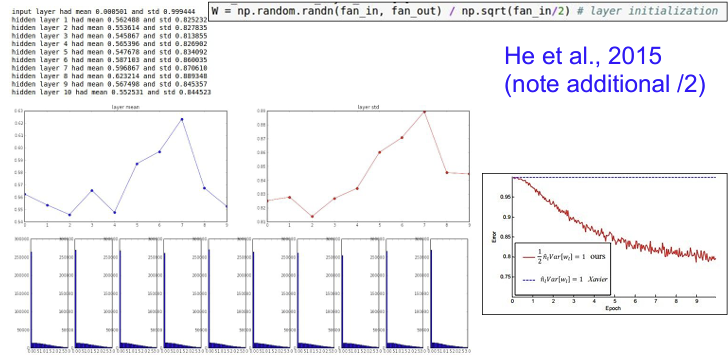
ReLU를 activation function으로 사용할 때는 Xavier initalization보다는 He initalization을 사용하는 것이 성능이 더 잘 나온다. He Initalization은 Xavier initalization에 단순히 sqrt(2)를 곱한 값이다. 직관적으로 ReLU는 음의 영역이 0이라 뉴런들 중 절반이 없어진다는 사실을 고려하기 위해서이다. 일제 입력은 반밖에 안들어가므로 반으로 나눠주는 term을 추가적으로 더해 주는 것이고 실제로 잘 동작한다.
4. Batch Normalization
Batch Normalization(배치 정규화)은 딥러닝에서 학습을 빠르고 안정적으로 만들기 위해 사용되는 정규화 기법이다.
신경망의 각 층에 들어가는 입력값의 분포를 일정하게 유지함으로써, gradient 흐름을 원활하게 만들고, 학습을 빠르게 수렴시킨다.


한 Batch 내에 각 차원별로 평균과 분산을 계산해서 Normalize한다. 그리고 이 연산은 Fully Conneted나 Convolutional Layer 이후에 넣어준다. 깊은 신경망에서는 각 layer의 W가 지속적으로 곱해져서 Bad scaling effect가 발생하게 되는데 Normalization은 이 bad effect를 상쇄시켜 버린다.
FC와 Conv layer에서 차이점이 있다면 Conv layer는 Normalization을 차원마다 독립적으로 수행하는 것이 아니라 같은 Activation Map의 같은 채널에 있는 요소들은 같이 normalization 해준다. 따라서 Conv Layer의 경우 Activation map(채널, Depth)마다 평균과 분산을 하나만 구한다.

하지만 Batch Normalization을 진행하는 경우 모든 출력이 정해진 분포(평균: 0, 분산: 1)을 가지게 되어 모델이 표현할 수 있는 값의 범위가 제한되게 된다. 그래서 Scale, Shift Parameter를 학습시켜 정규화된 값을 다시 확장하고 이동할 수 있도록 해준다. 이렇게 γ, β를 도입하면 모델이 원하는 분포로 되돌릴 수 있게 된다. 즉, 신경망이 데이터를 tanh에 얼마나 saturation 시킬지를 학습하기 때문에 유연성을 얻을 수 있다.
극단적인 예시로 신경망이 학습을 통해 γ = √σ², β = μ로 만들면 결과적으로 정규화를 하지 않은 것과 동일한 출력이 된다.
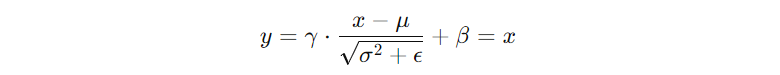
이의 경우에는 신경망이 "이 경우에는 정규화를 안하는 것이 낫다"는 판단을 스스로 한 것이다.



5. Babysitting the Learning Process
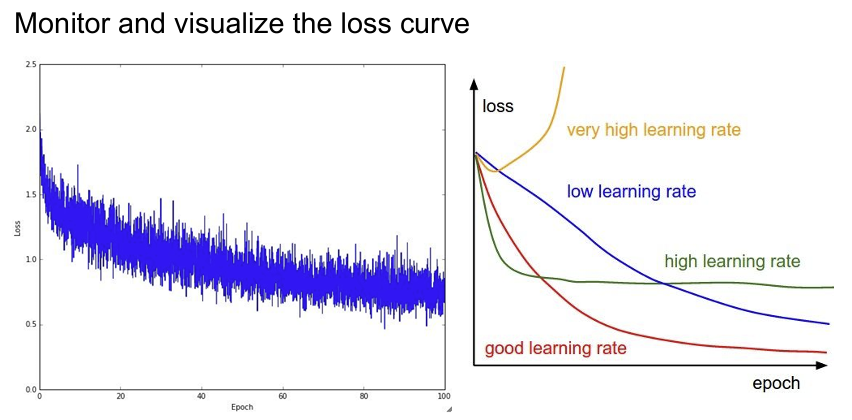
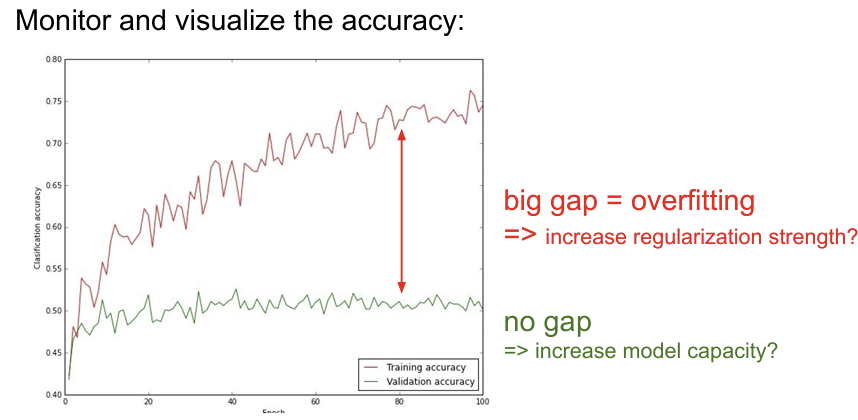
모델의 좋은 성능을 얻기 위해서는 학습 도중 자주 확인하고, 하이퍼파라미터나 훈련 조건을 조정해주는 반복적인 작업을 진행해야한다. 처음 시작할 때 좋은 방법은 regularization을 0으로 설정하고 데이터의 일부만 학습시켜 보는 것이다. 데이터가 적으면 당연히 overfitting이 생길 것이고 Loss가 많이 줄어들 것이다. 이렇게 Loss가 꾸준히 잘 내려가는지 확인하고 동시에 Train Accuracy는 증가하는지를 확인한다.
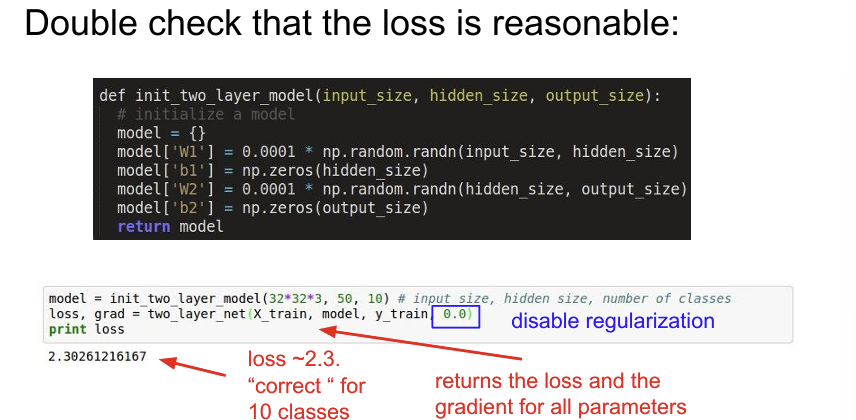
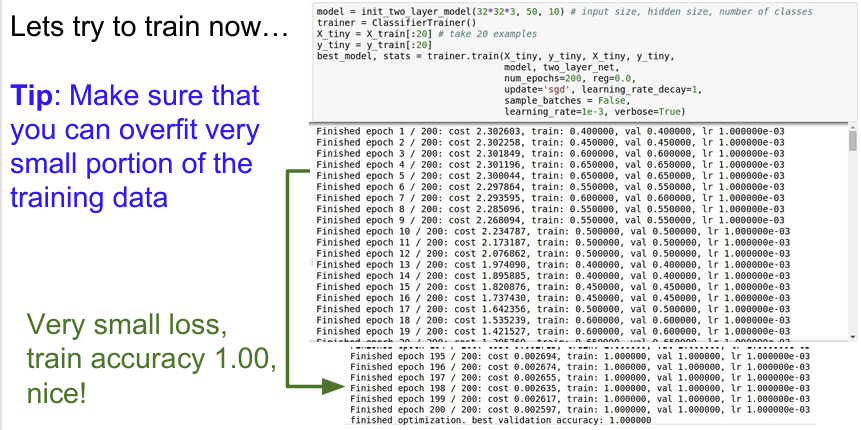
학습을 본격적으로 시작할 때는 regularization을 약간만 주면서 적절한 learning rate를 찾아야한다. learning rate는 가장 중요한 hyperparameter 중 하나이기 때문에 가장 먼저 정해야만 한다. 직므은 학습률이 1e-6으로 아주 작기 때문에 loss가 좀처럼 변하지 않는 것을 알 수 있다.
여기에서 유심히 살펴봐야 할 점은 loss가 잘 변하지 않음에도 training/validation accuracy가 20%까지 급상승한 것이다. 이 현상은 어찌됐든 model이 조금씩 옳은 방향으로 학습을 진행하고 있고, Accuracy는 가장 큰 값만을 취하기 때문에 크게 뛸 수 있는 것이다.

learning rate를 크게 키우고 결과를 보면 cost가 NaN임을 알 수 있다. NaN이라는 것은 cost가 발산(exploded)한 것이다.

6. Hyperparameter Optimization

parameter 값을 샘플링할때 10^-3 ~ 10^-6 을 샘플링하지 말고 10의 차수 값만 샘플링하는 것이 좋다.(-3 ~ -6) 왜냐하면 learning rate는 gradient와 곱해지기 때문에 learning rate의 선택 범위를 log scale을 사용하는 편이 좋다. 따라서 차수(orders of magnitude)을 이용하는 편이 좋다.
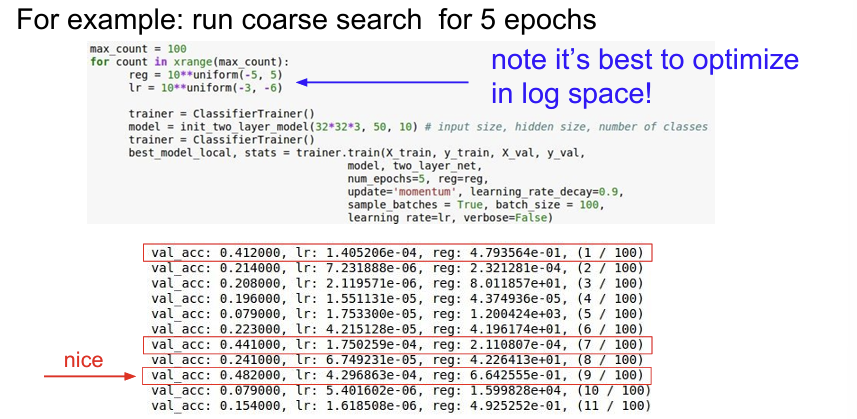
아래는 가장 좋은 Accuracy를 찾은 경우이다. 하지만 잘 보면 good learning rate는 전부 10e-4 사이에 존재하고 있음을 알 수 있다. Learning rate의 최적 값들이 현재 설정한 범위의 경계부분에 집중되어 있다는 것을 알 수 있다. 이렇게 되면 실제로 최적의 값이 1e-5나 1e-6 근처에 존재할 수도 있는 것이다. 이런 경우에는 탐색 범위를 조금 이동시킨다면 더 좋은 범위를 찾을 가능성이 있다.

model의 loss를 관찰하면서 현재 learning rate의 값이 큰지 작은지를 확인하도록 한다.