
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- cs231n
- Multi-Head Attention
- Optimization
- Transformer
- deep learning
- SQLD
- Machine Learning
- DFS
- Generative Models
- C++
- Regularization
- assignment1
- computer vision
- Baekjoon
- RNN
- 밑바닥부터 시작하는 딥러닝2
- Algorithm
- 딥러닝
- Adam
- do it! 알고리즘 코딩테스트: c++편
- dropout
- CPP
- mask r-cnn
- Python
- Alexnet
- marchine learning
- assignment2
- CNN
- BFS
- 밑바닥부터 시작하는 딥러닝
- Today
- Total
newhaneul
[Seoul National Univ: ML/DL] Lecture 14. Convolutional Neural Network 본문
[Seoul National Univ: ML/DL] Lecture 14. Convolutional Neural Network
뉴하늘 2025. 3. 29. 19:20본 포스팅은 서울대학교 이준석 교수님의 M3239.005300 Machine Learning & Deep Learning 1을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
이준석 교수님에게 강의 자료 사용에 대한 허락을 받았음을 알립니다.
https://youtu.be/poxVMbBVbkU?si=we1lyc5WToBhfsuD
0. 들어가기 전에..
이전 Lecture에서 배운 Fully Connected layer의 경우 아래의 신경망 구조를 띤다고 하였다.

CNN에 대해 들어가기 전에 이미지로부터 패턴을 인식하는 방법에 대해 생각해보자. 만약 이미지로부터 찾고자 하는 패턴이 있다면 그 패턴에 높은 score를 주는 filter를 설정하면 될 것이다. 그리고 우리는 이미지에서 패턴이 어디에 있는지, 얼마나 큰지를 모르기 때문에 전체 이미지에 걸쳐서 다양한 크기의 filter를 적용해봐야 한다.

CNN은 어떻게 특정 패턴을 잘 인식하도록 filter를 구현 할 수 있을지에 대해 생각해보는데에 출발한 신경망이다.
Convolutional neural network은 2가지 가정을 세운다.
1. Spatial locality: 이미지에서, 픽셀 하나는 멀리 떨어진 픽셀보다는 주변 픽셀들과 더 강한 상관관계를 가지므로 input 이미지의 일부 영역(filter size)만을 보며 local pattern을 학습하고, 이를 통해 전체 이미지를 이해할 수 있도록 한다.
2. Positional invariance: input 이미지 내의 특정 feature는 어디에 위치하든 동일한 의미를 가지므로 공유된 filter를 사용하여 입력 전체에 걸쳐 동일한 연산을 수행하도록 한다. 즉, 이를 통해 feature의 위치가 달라도 동일하게 인식할 수 있게 된다.

1. Convoutional Layer
Convolutional Neural Network(CNN)은 주로 이미지, 영상, 음성 등의 공간적 구조를 가지는 데이터를 처리하기 위해 고안된 인공신경망의 한 형태이다. CNN은 일반적인 Fully-Connected Neural Network와는 달리, 입력 데이터의 지역적인 특징을 효율적으로 추출하고, 파라미터 수를 크게 줄일 수 있는 구조를 가지고 있다.



CNN은 결국 여러개의 layer를 쌓아 Low-level features로 Mid-level features를 구별할 수 있도록 하고, Mid-level feature로 High-level features를 구별할 수 있도록 하며, 마지막으로 High-level Features로 최종 Classification을 진행하는 신경망이다.
각 수준의 features를 확인해보면 처음에는 edge 수준이였던 features가 점점 구체화되고 있음을 알 수 있다.

이 CNN에는 2가지 문제가 존재하였다.
1. filter의 size가 크다면, output인 activation map이 빠르게 줄어들게 되는 문제가 있다. 이러한 문제는 layer를 많이 쌓지 못하도록 하는 문제가 있다.
-> Padding 기법으로 해결
2. input image의 size가 크다면 filter를 사용한다고 해도 너무 많은 계산을 진행해야 하는 단점이 있다.
-> Stride 기법으로 해결

2. Convolutional Layer: Stride
Stride는 filter(커널)를 몇 칸씩 이동시키면서 합성곱 연산을 할지를 결정하는 값이다. 기본적으로 stride는 1이며, 값이 커질수록 activation map(feature map)의 크기가 줄어들게 된다.
stride는 출력 크기와 계산량을 줄이고, 메모리 사용을 효율적으로 하기 위한 목적으로 사용된다.

3. Convolutional Layer: Padding
Padding은 입력 데이터의 가장자리에 인위적으로 0을 추가하는 기법이다. 주로 입력 크기를 유지하거나, 경계 정보 손실을 막기 위해 사용된다.
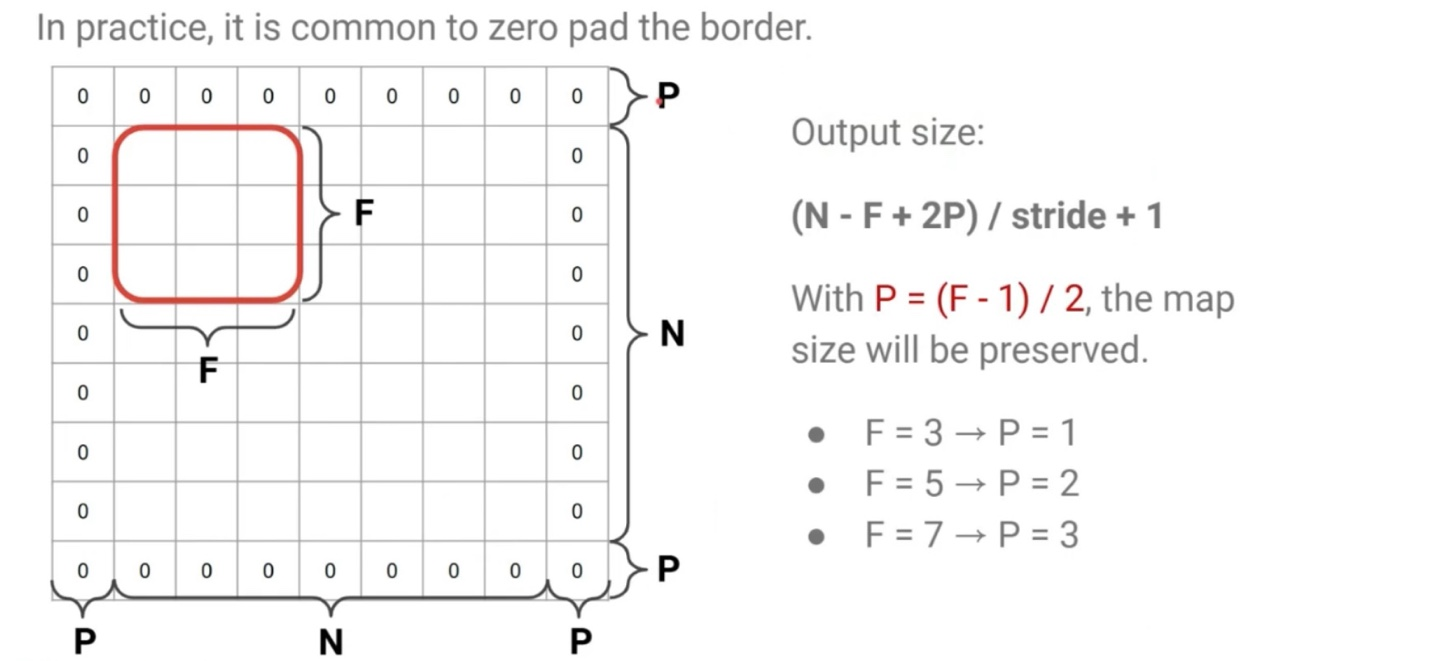
따라서 Padding을 추가하면 출력 크기를 조절하거나 동일하게 유지할 수 있게 된다.

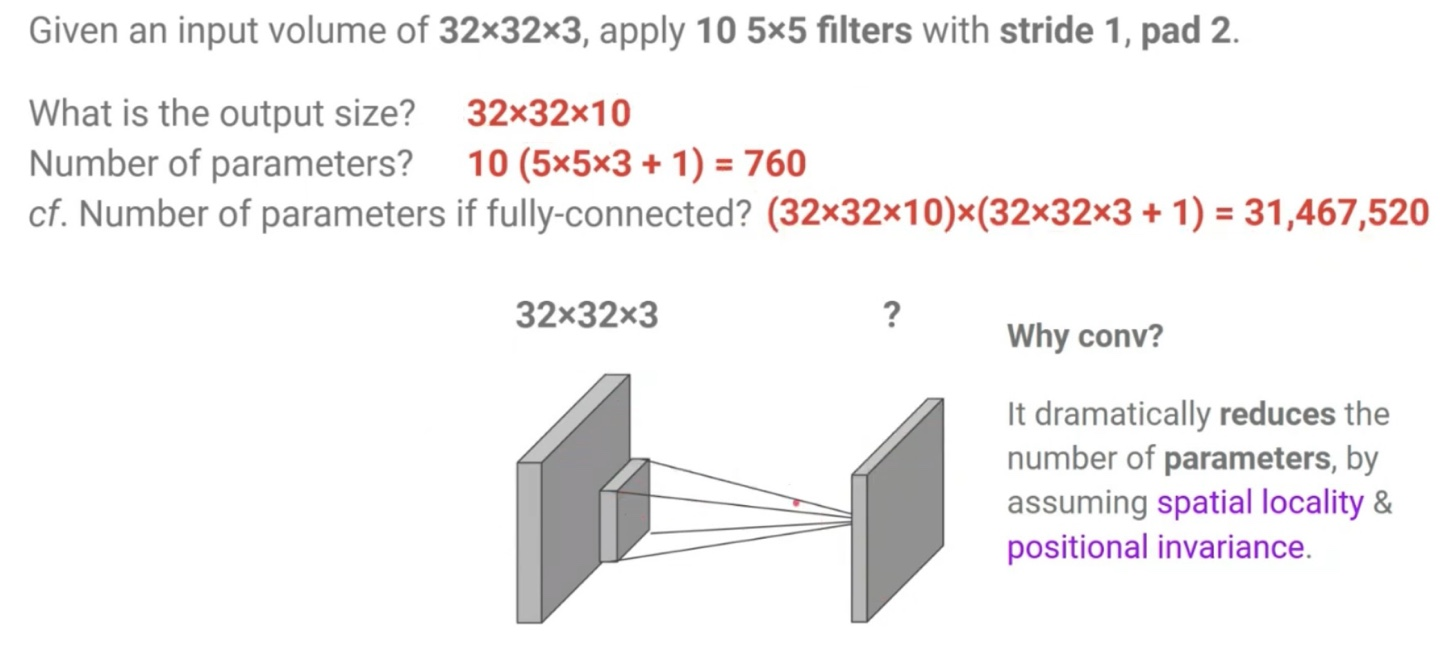
32 x 32 x 3의 input image가 주어졌을때, 10개의 5 x 5 x (3) filters로 stride = 1, pad = 2인 상황에서의 output size는 공식을 통해 쉽게 구할 수 있다. (32 - 5 + 2 * 2) / 1 + 1 = 32 -> 32 x 32 x 10
CNN의 parameter는 filter의 size와 개수, 편향을 고려해야하므로 (5 x 5 x 3 + 1) x 10 = 760개임을 알 수 있다.
만약 Fully-connected 상황이라면 parameter의 개수는 output size와 input image의 size의 곱 만큼 존재하므로 (32 x 32 x 3 + 1) x (32 x 32 x 10) = 31,467,520개임을 알 수 있다.
이를 통해 CNN이 Fully-connected보다 엄청나게 효율적임을 알 수 있는데, 그 이유는 CNN이 가정하는 spatial locality와 positional invariance 때문이다.
CNN에서 filter size를 1 x 1로 정하고 사용하는 경우도 있는데, 이러한 경우는 다소 직관적이지 않지만, 공간적 정보는 유지한 채, 채널 수를 조정하고 싶을 때 사용할 수 있다.

CNN의 output size 연산을 정리해보면 아래와 같다.

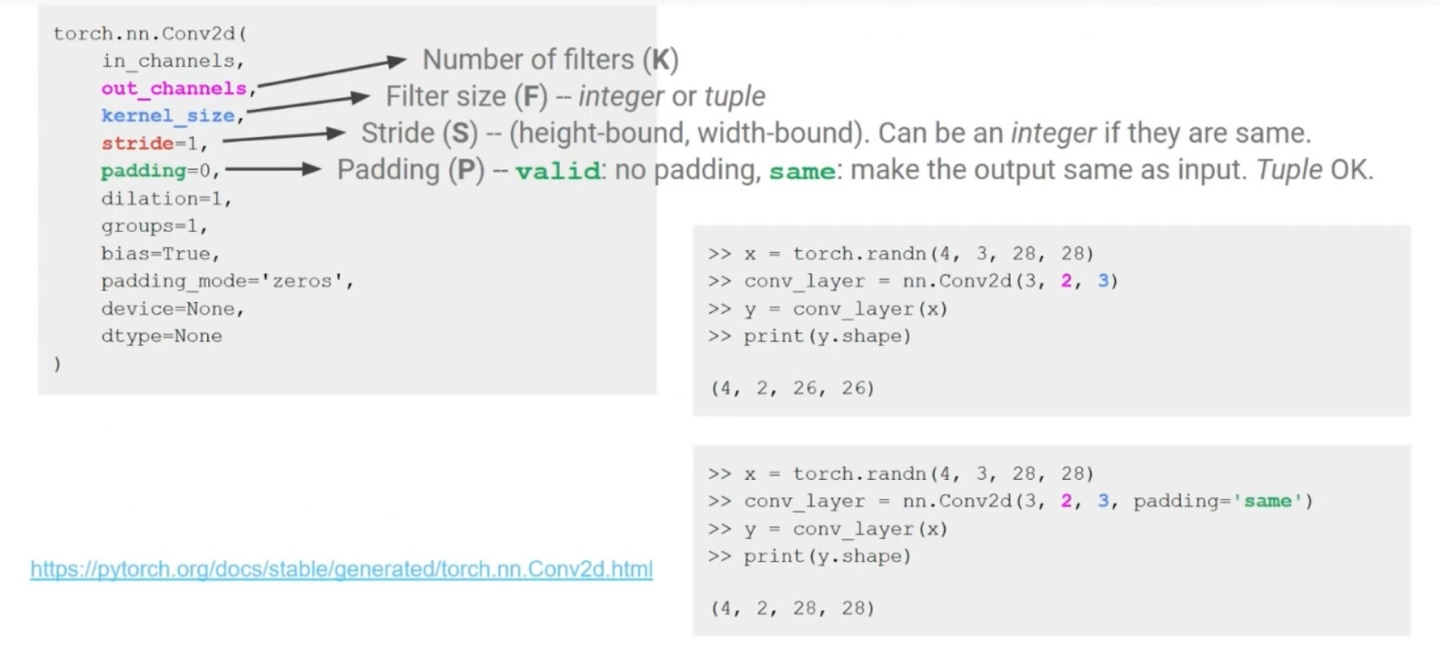
Convolutional layer는 Fully connected layer의 special case이다. 왜냐하면 fully connected layers는 모든 input value들을 통해 output을 결정하는 general한 경우이고, convolutional layer는 filter size만큼의 input value들로 output을 결정하기 때문이다.
즉, Convolutional layer는 filter의 범위 외에 가중치 값이 전부 0인 fully-connected layer와 동일하다.
하지만 사실은 Fully connected layer도 convolutional layer에 속해있다. 만약 convolutional layer의 filter size가 input data의 size와 동일하다면 결국에는 fully connected layer와 완전히 동일해지게 된다.

4. Convolutional Layer: Pooling Layer
Pooling layer는 activation map의 크기를 줄이면서 중요한 정보만 유지하는 Downsampling 작업을 진행한다. 주로 사용하는 Pooling은 Max Pooling과 Average Pooling이다.
Pooling layer는 기존의 activation map을 sampling하는 것이므로 hyperparameter가 없는 layer이다.
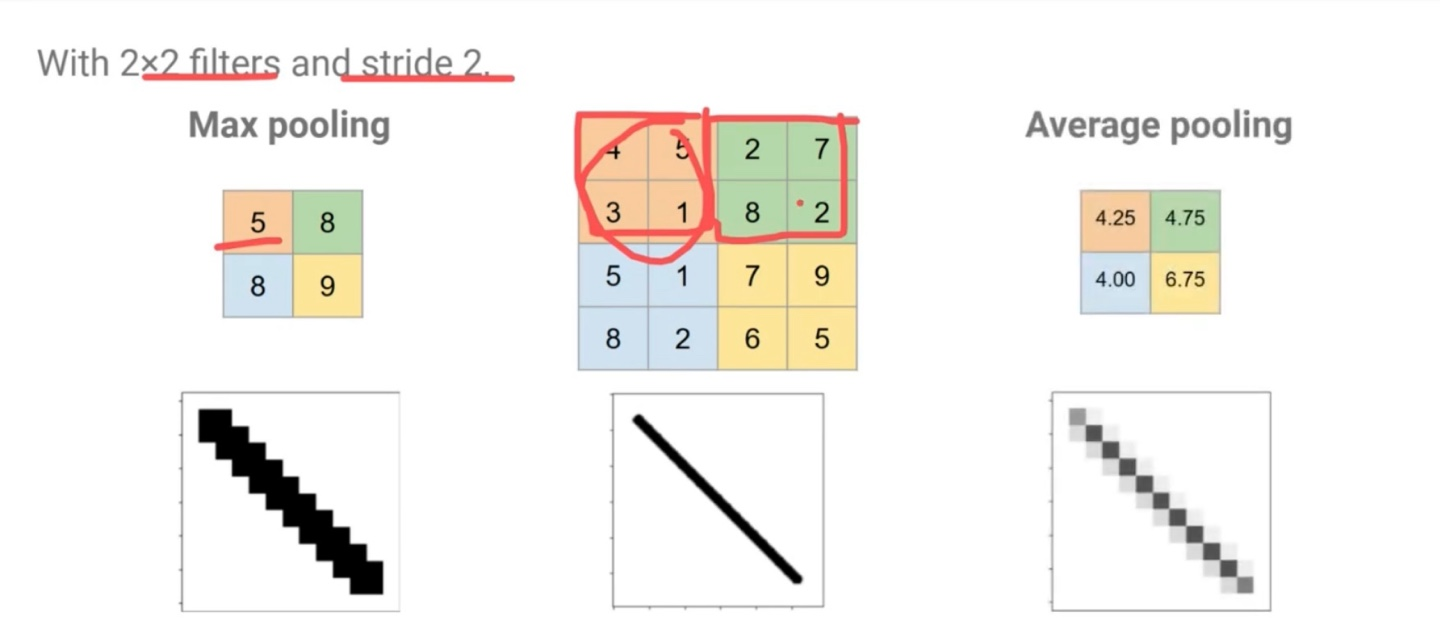

Pooling layer는 downsampling을 통해 더 작고 관리하기 쉽도록 축소시킨다. 또한 노이즈를 어느정도 제거고 overfitting을 제어하는 효과가 있다. 각 activation map은 독립적으로 작동하게 된다.

Pooling layer를 거치게 되면 output size는 아래와 같이 바뀌게 된다. 앞서 말했듯 pooling은 학습이 일어나지 않으므로 hyperparameter 개수가 0개이다.

5. Convolutional Neural Network(CNN) Example: AlexNet
AlexNet은 2012년 ImageNet 챌린지(ILSVRC 2012)에서 딥러닝의 가능성을 전 세계에 알린 역사적인 CNN 구조이다. 그 전까지는 전통적인 머신러닝 방법들이 주를 이루었으나, AlexNet은 당시 기준으로 압도적인 성능 향상을 보여주며 딥러닝 열풍을 일으켰다.
신경망 구조는 Conv Layer 5개, Fully Connected Layer 3개로 구성되어있다. 활성화 함수는 ReLU를 사용하였고, Max Pooling과 Dropput, Local Response Noramlization을 적용하였다.





