| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- assignment1
- Positional Encoding
- RNN
- computer vision
- CNN
- Regularization
- Alexnet
- Transformer
- assignment2
- Python
- Multi-Head Attention
- Optimization
- BFS
- cs231n
- Adam
- C++
- DFS
- Algorithm
- mask r-cnn
- Baekjoon
- do it! 알고리즘 코딩테스트: c++편
- marchine learning
- Machine Learning
- deep learning
- dropout
- 밑바닥부터 시작하는 딥러닝
- 딥러닝
- SQLD
- CPP
- 밑바닥부터 시작하는 딥러닝2
- Today
- Total
newhaneul
[Seoul National Univ: Computer Vision] Lecture 16. Metric Learning 본문
[Seoul National Univ: Computer Vision] Lecture 16. Metric Learning
뉴하늘 2025. 6. 15. 20:48본 포스팅은 서울대학교 이준석 교수님의 M3224.000100 Machine Learning for Visual Understanding을 수강하고 공부한 내용을 정리하기 위한 포스팅입니다.
https://www.youtube.com/watch?v=MVYxgJGc92g
1. Metric Learning
Metric Learning은 입력 샘플 간의 유사도(similarity) 또는 거리(distance)를 학습하는 방법으로, 비슷한 것끼리는 가까이, 다른 것끼리는 멀리 배치하도록 학습하는 기술이다. 즉, 거리 공간 상에서 의미 있는 표현(embedding)을 학습한다. 분류(classification)이나 검색(retrieval) 문제에서 효과적이다.
Metric Learning Data는 거리 기반 학습(metric learning) 모델을 학습시키기 위해 설계된 쌍(pair) 또는 삼중(triplet) 형태의 데이터셋을 의미한다. 이 데이터는 두 샘플이 같은 클래스(positive)인지, 다른 클래스(negative)인지에 대한 정보를 포함한다.




metric learning에서 label이 있는 data 보다 수집이 더 쉬운 상대적 유사도 데이터를 사용한다. 같은 장소, 검색 엔진 결과 상위 이미지들, 동시에 클릭된 상품들로부터 positive pair을 쉽게 수집할 수 있고, data augmentation으로도 만들어낼 수 있다. 하지만 이렇게 수집한 data들은 noise가 있다는 것을 염두해야한다.

Metric Learning은 supervised learning이지만, 사람의 직접적인 라벨링 없이 수집한 유사도 정보 data로 학습이 가능하다.

2. Learning to Rank (Ranking) Problem
Learning to Rank의 목표는 학습 데이터의 정렬 패턴을 일반화하여 새로운 리스트에 대해서도 적절한 정렬 순서를 산출하는 것을 목표로 한다. LTR과 관련된 대표적인 metric learning 방식으로는 Triplet loss, Contrastive learning이 있다.


Problem Formulation
Point-wise Ranking
- (Query, Item) → 실수 점수(numerical) 또는 순위 레이블(ordinal)
- 각각의 (Query, Item) 쌍에 대해 점수를 예측
Pair-wise Ranking
- (Query, Item A, Item B) → A가 B보다 선호됨 (A > B)
- 모델이 주어진 Query에 대해 Item 간 상대적인 순서를 예측하여 순위를 보존하도록 학습한다.
- 순위가 바뀌는 것(inversions in ranking)을 최소화시키는 것이 목표
List-wise Ranking
- (Query, Item List) → 순위가 지정된 여러 아이템들
- 임의의 Query에 대해 올바르게 정렬된 순위 리스트를 만드는 것을 목표
- 계산이 불가능한 경우가 많기 때문에 Pair-wise를 활용함
- NDCG로 직접 최적화 가능

Ranking for Representation Learning
LTR 모델의 학습 목적은 단순히 정렬만이 아니라, 일반화 가능한 표현을 학습하는 데 있다. 즉. 훈련된 정렬 능력이 보지 못한 Query/Item에도 일반화되기를 기대한다.

Evaluation Metrics: Normalized Discounted Cumulative Gain (NDCG)
NDCG는 가장 널리 사용되는 정렬 성능 평가 지표 중 하나이다. 높은 순위에 더 관련성 있는 항목이 있을수록 점수가 높아지게 되고, Graded relevance를 고려한 평가 지표이다.
DCG(Discounted Cumulative Gain)

- rel: i 번째 출력 항목의 관련성 (Query와 관련성이 있다면 1, 그 외에는 0)
- i: 순위
- 순위가 낮을수록 (i가 클수록) 덜 중요하기 때문에 기여도가 log 감소되는 형태
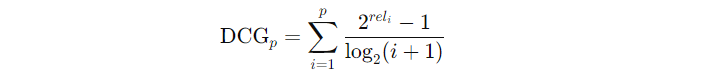
NDCG(Normalized Discounted Cumulative Gain)

- IDCG: GT에 따라 relevance 기준으로 최적 정렬했을때의 DCG (가장 이상적인 정렬에서의 DCG)
- 항상 0~1 사이의 값


3. Triplet Loss
Tiplet Loss란 embedding 공간에서 Anchor와 Positive는 가깝게, Anchor와 Negative는 멀어지도록 학습하는 손실 함수이다.

- x^a: Anchor value
- x^p: 같은 클래스의 Positive value
- x^n: 다른 클래스의 Negative value
- : 임베딩 함수
- : margin, 즉 구별해야 하는 최소 거리 차이
- : hinge function, 0보다 작으면 0으로 처리됨
Dist(anchor, positive)의 거리는 줄이도록 학습시켜야하기 때문에 양수, Dist(anchor, negative)의 거리는 멀어지도록 학습시켜야하기 때문에 음수. 즉, Dist(a, p) + α < Dist(a, n)을 만족하도록 학습 → 그래야 Loss = 0

Positive pair
- anchor, positive pair는 보통 implicit data collection이나 human labeling으로 수집된다.
Negative pair
- negative pair는 보통은 수집하지 않고, 랜덤하게 추출하는 것이 특징이다.
- 그러나 임의로 추출한 negative pair는 hard negative problem에 대해 성능이 매우 낮다. 그 이유는 임의로 추출한 데이터이기 때문에 대부분이 anchor와 너무 멀리 떨어져 있어 학습에 도움되는 데이터가 거의 없다. 따라서 학습 초기에만 효과적이고 이후에는 gradient가 거의 없는 것이 문제이다.


Online Negative Mining
따라서 성능이 떨어지는 랜덤한 negative pair를 사용하는 것이 아니라, 현재 미니배치 내에서 가장 헷갈리는 negative를 anchor에 대해 동적으로 찾아서 재할당 하는 아이디어를 사용한다. → Hard Negative Mining from Batch
- Anchor마다 모든 다른 샘플과 거리 계산 (k-NN)
- Dist(f(x^a), f(x^i)) for all i ≠ a
- Positive가 아닌 것 중 가장 가까운 것을 Hard Negative로 설정
- 명시적 라벨이 있다면 다른 클래스 중 가장 가까운 샘플
- 기존 Negative를 새로 찾은 Hard Negative로 교체
- 이 과정을 현재 배치 내의 모든 Anchor에 대해 반복

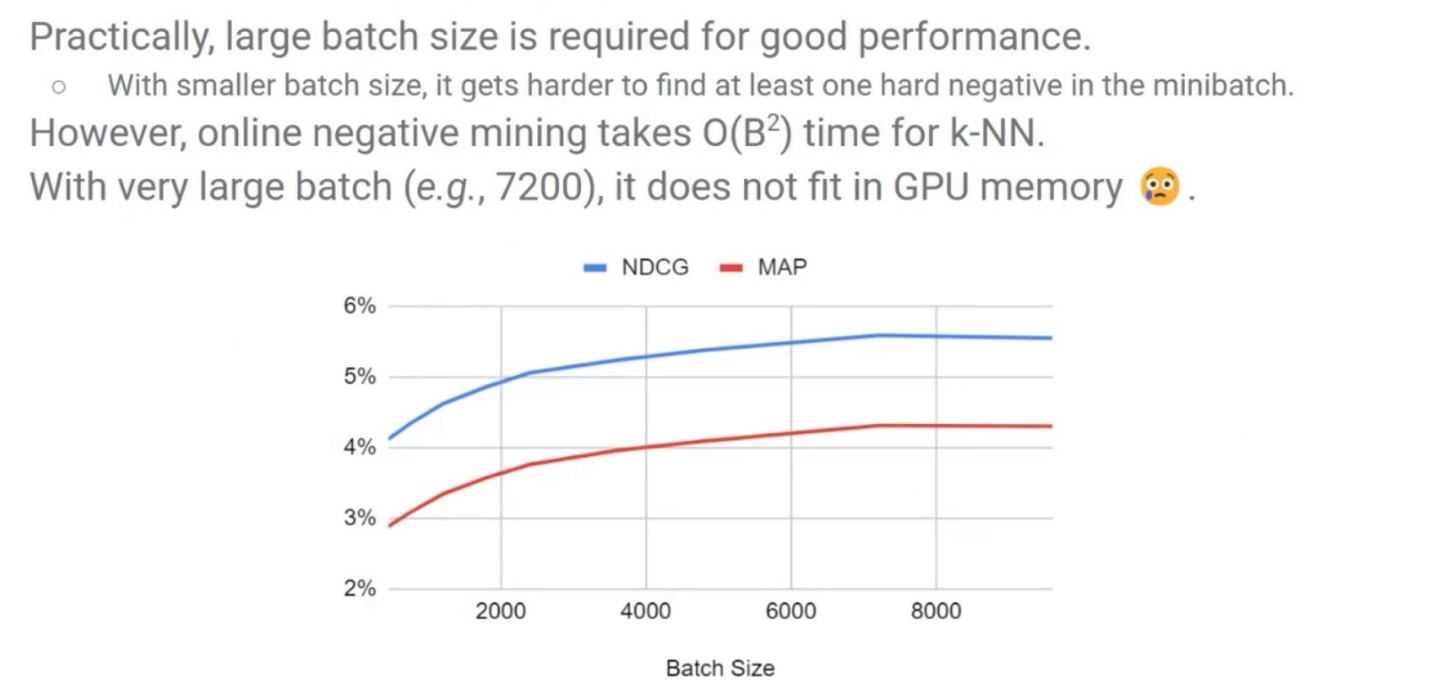
Hard Negative Mining 방식은 현재 Batch 내의 모든 다른 샘플과의 거리를 계산한 뒤 그중에서 가장 가까운 것을 Hard Negative로 설정하기 때문에, Batch size가 클수록 성능이 높아질 수 밖에 없다. Hard Negative를 더 잘 찾을 확률이 높아지기 때문.
보통은 7200 정도의 batch size에서 가장 성능이 높지만, GPU memory에 로드가 불가능하다는 문제가 있다.
Semi-hard Negative Mining
그렇지만 항상 Hard negative를 사용하는 것은 문제가 발생할 수 있다. Triplet Loss의 수식은 아래와 같았다.
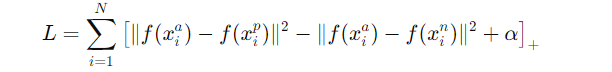
그리고 이 손실 함수에서 아래를 만족하도록 학습하는 것이 목표였다.
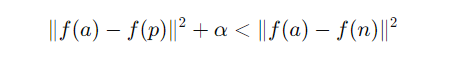
Hard Negative (n1)

Anchor와 가장 가까운 Negative를 구별하도록 하게 되면, 손실 함수는 d(a, n)을 증가시키는 것이 아니라 아예 모든 임베딩 f(x)를 0으로 만들어서 거리 자체를 없애버리도록 학습하는 문제가 발생할 수 있다.
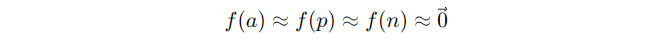
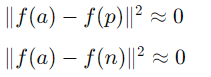

모델 입장에서는 margin 조건을 만족시키는 것이 어렵기 때문에 이 방법이 손실 함수를 감소시키는 가장 쉬운 방법이라 생각하게 된다. 그 결과 모든 벡터를 0에 수렴시키는 방향으로 학습하여 손실을 줄이려 하는 것이다.
Semi-Hard Negative (n2)
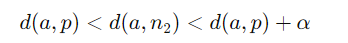
- Positive보다 멀지만 margin보다 가까운 Negative
- 손실은 있지만 gradient가 적절히 작동해 실제로 학습이 잘 진행된다.
Easy Negative (n3)
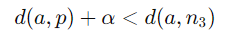
- 이미 margin 외부에 있어서 Loss = 0이기 때문에 학습 신호가 없다.
따라서 Negative는 Anchor와 Positive 간 거리보다 약간 더 먼 위치에서 선택해야 한다.

FaceNet(2015)
얼굴 이미지를 고정된 차원의 임베딩 벡터로 매핑하여, 유클리드 거리만으로 두 얼굴이 같은 사람인지 아닌지를 판단할 수 있도록 학습하는 모델이다.

FaceNet: Architecture
- ZFNet or GoogLeNet
- L2 Normalization
- 128-dims Embedding → 얼굴 이미지를 128차원의 단위 벡터로 변환하여 임베딩 공간 내 거리 기반 판단이 가능
- Triplet Loss → Anchor, Positive, Negative 세 얼굴을 이용해 아래 조건이 만족되도록 학습


FaceNet: Result
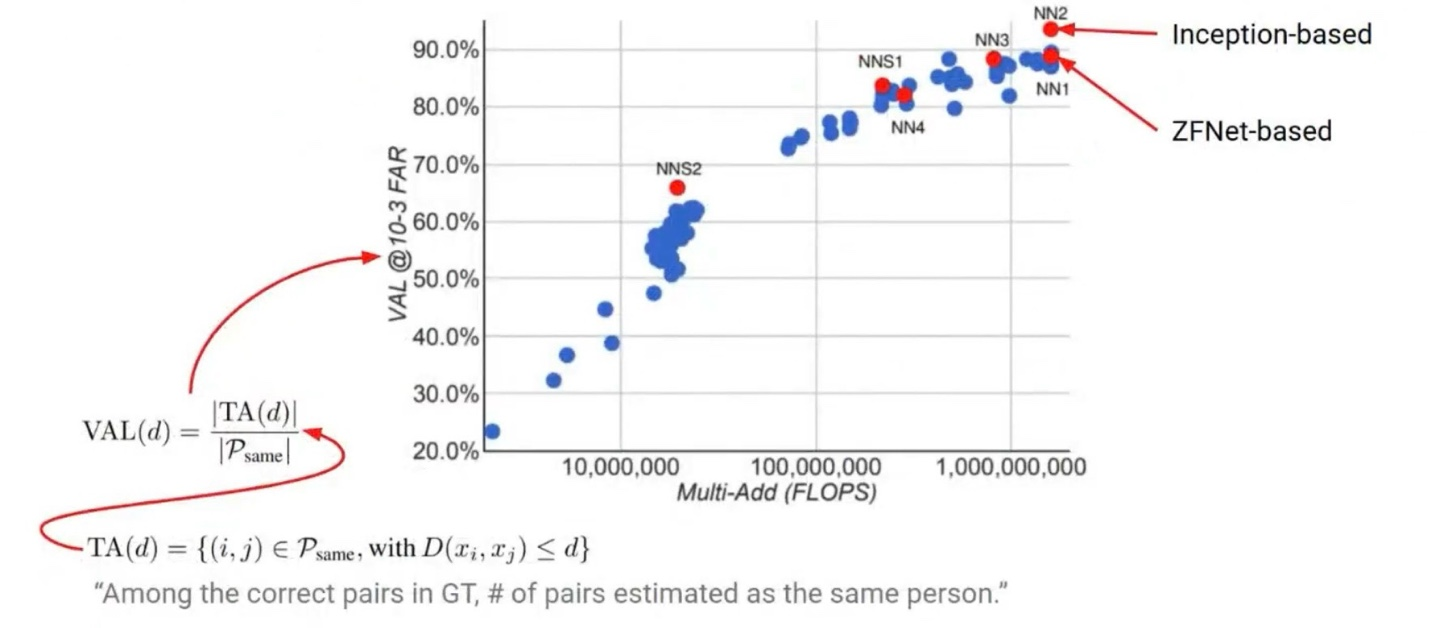
FaceNet: Examples


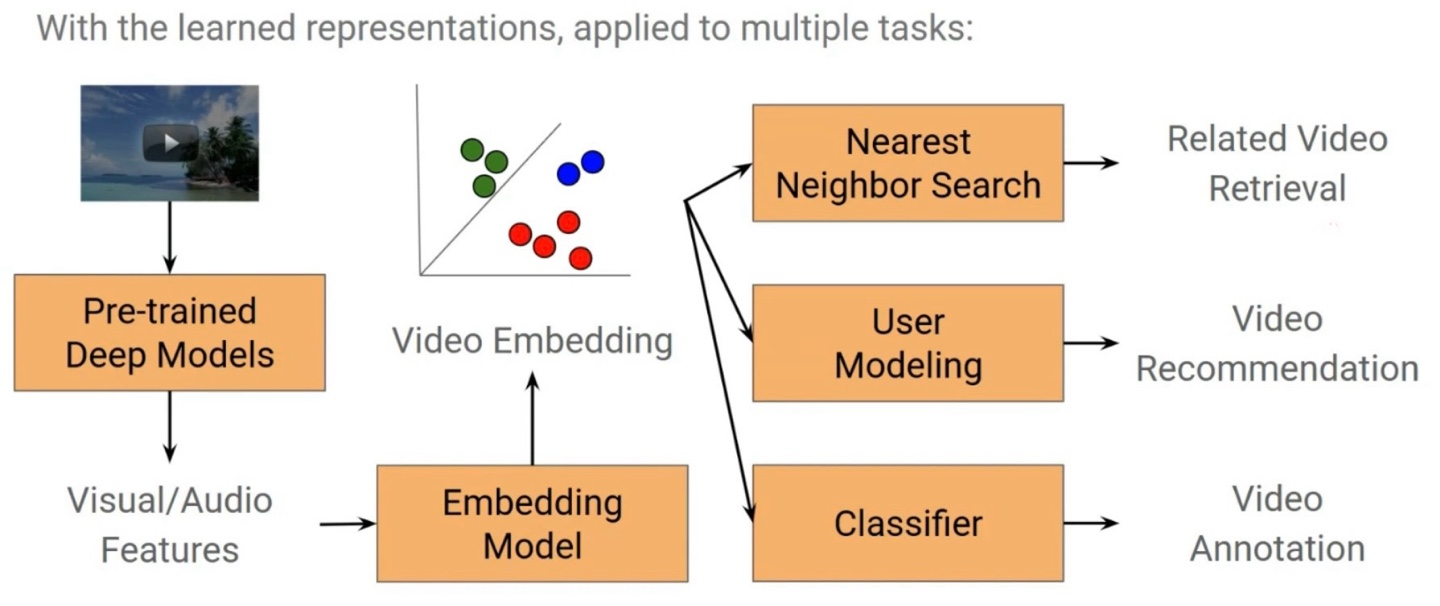
CDML (Collaborative Deep Metric Learning)
이미지(또는 동영상)를 고차원 임베딩 공간에 매핑한 뒤, 비슷한 콘텐츠일수록 가까운 위치에 오도록 학습한다.

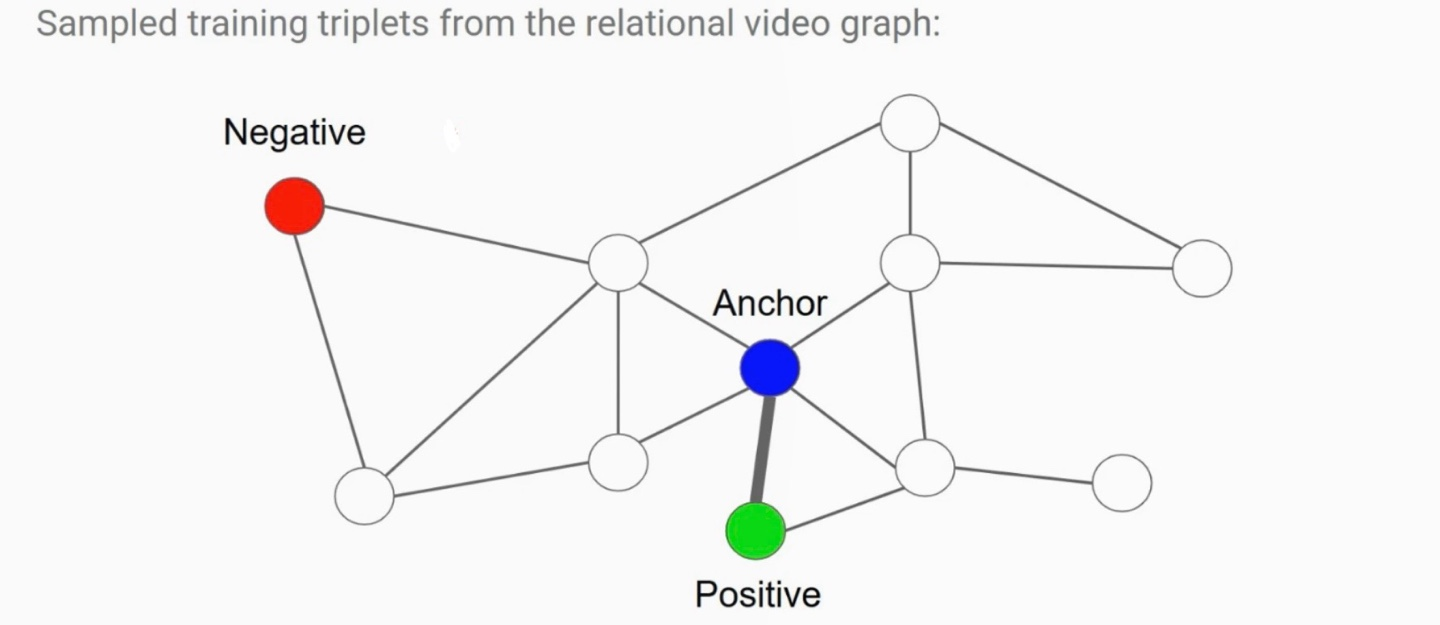
Relational video graph에서 Triplet (Anchor, Positive, Negative)을 샘플링
- Anchor: 기준이 되는 비디오
- Positive: Anchor와 연결된(co-watched 등) 관련 비디오
- Negative: Anchor와 직접적인 연결이 없는 비디오 (다른 하위그래프에 위치)
CDML (Collaborative Deep Metric Learning): Architecture
동영상 데이터를 Video + Audio feature로 나눠서 학습한 뒤 마지막에 결합하고 Tiplet Loss로 학습
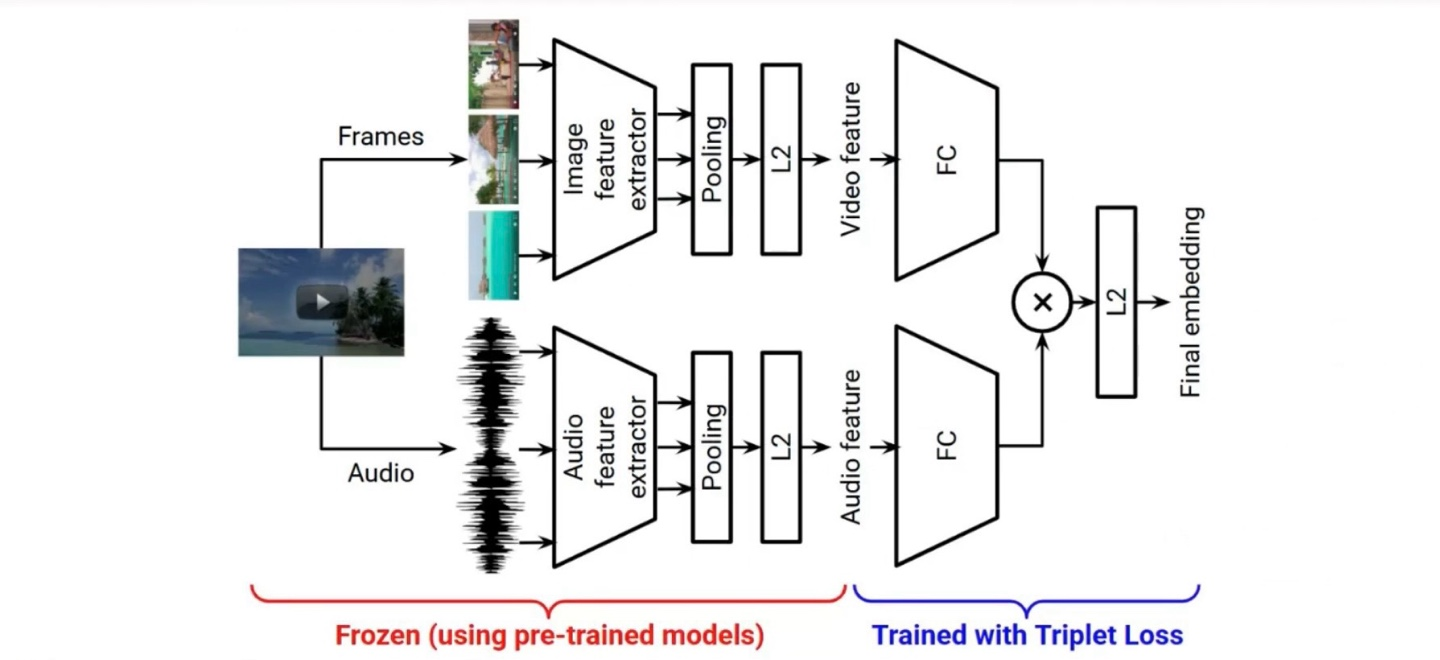
CDML (Collaborative Deep Metric Learning): Examples

CDML (Collaborative Deep Metric Learning): Limitations

GCML (Graph Clustering Metric Learning)
CDML에서는 랜덤으로 선택한 negative를 사용했다면, GCML에서는 전체 relational video graph에 대해 가까운 negative를 선택한다.
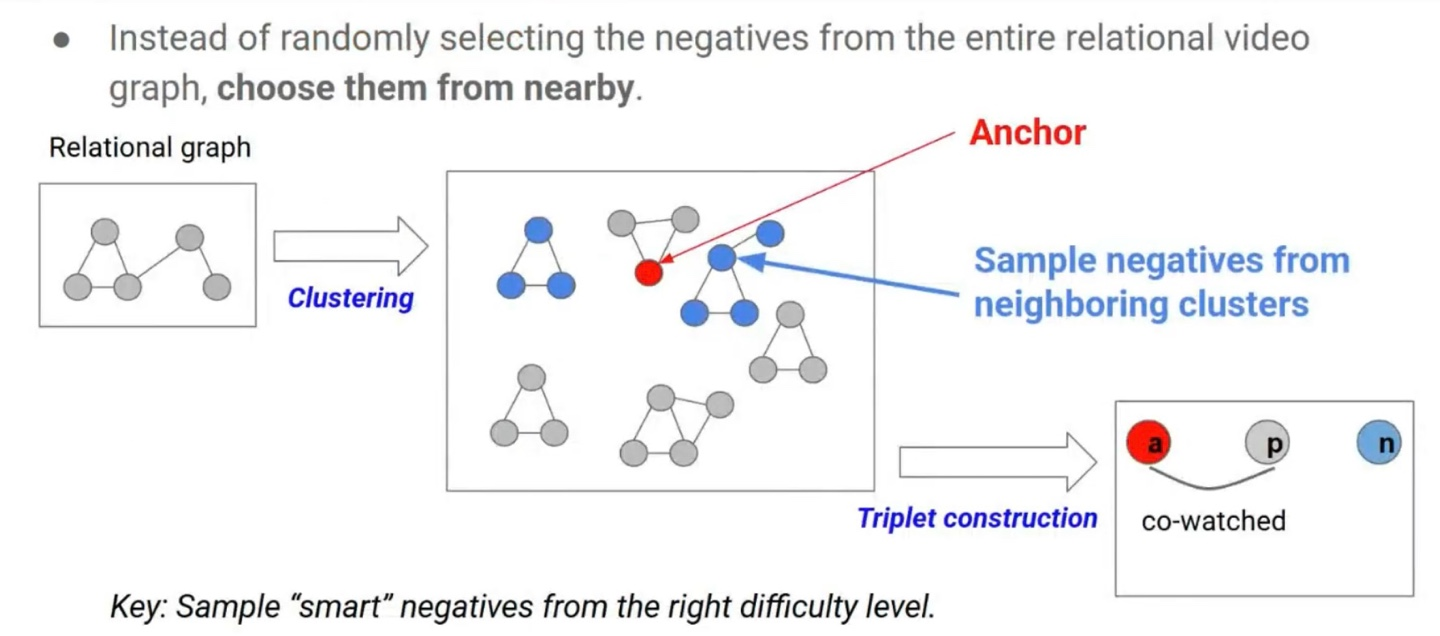
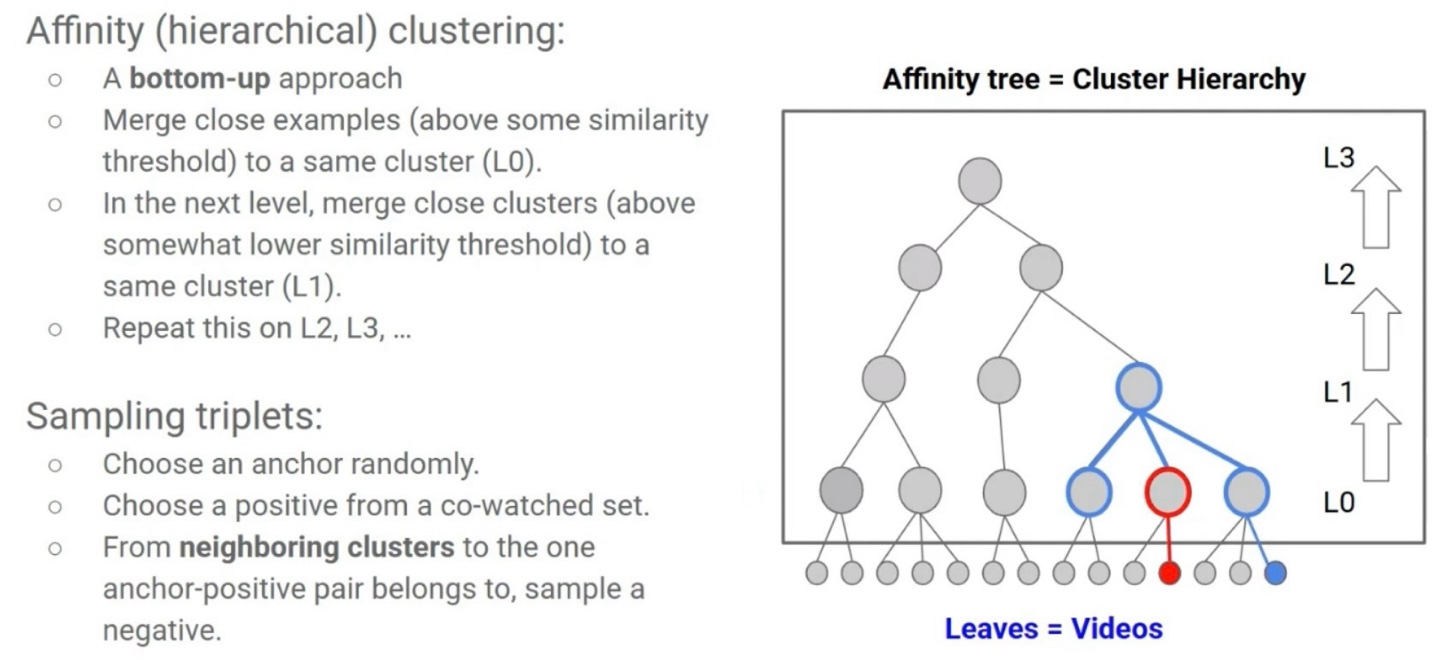
GCML (Graph Clustering Metric Learning): Discussions
random negative를 사용한 CDML보다 가까운 negative를 선택하여 학습한 GCML이 더 효율적으로 학습을 진행했음을 알 수 있다.

4. Contrastive Learning
Contrastive Learning은 데이터를 pair로 구성해, 서로 유사한 것끼리는 가까이, 다른 것끼리는 멀리 임베딩되도록 학습하는 표현 학습 기법이다. 자주 사용하는 손실 함수로는 Contrastive Loss와 NT-Xent(SimCLR)이 있다.
- Positive Pair: 같은 객체, 같은 클래스, augment된 같은 이미지 등
- Negative Pair: 다른 객체, 다른 클래스, 다른 인스턴스
보통의 손실 함수는 Y = 0: similar pair, Y = 1: dissimilar pair가 주어졌을 때, Y = 0인 경우 similar case를 적용하고, Y = 1인 경우 dissimilar case를 적용하는 구조이다.
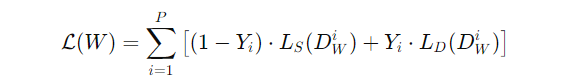
아래의 식은 손실 함수의 예시이다.


input 샘플 X가 similar pair일 경우 Y = 0으로, dissimilar pair일 경우 Y = 1을 할당한다.
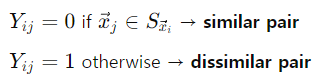
이제 Y를 할당하였으면 Optimization을 진행한다. 모든 pair에 대해 Y = 0인 경우(similar pair)에는 D_W를 줄이도록 W를 업데이트하고, Y = 1인 경우(dissimilar pair)에는 D_W를 증가시키도록 W를 업데이트한다.
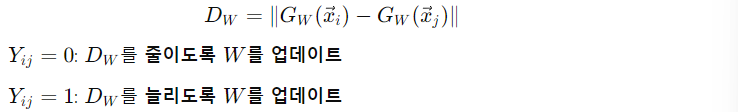

Recall: Normalization Problem
지금까지 classification 문제들은 class의 수가 적었기 때문에 모든 class에 대해 score를 계산하는 softmax가 문제가 되지 않았다. 그러나 큰 이미지나 영상 분류 모델을 학습한다고 가정하면, 10만개 이상의 class로 classification을 진행해야 하고 이때는 모든 문제가 발생하게 된다. Cross-Entropy Loss나 Softmax들은 모든 파라미터가 gradient를 받기 때문에 매 학습마다 전체 파라미터 업데이트가 필요하게 되고 이로 인해 학습 병목이 발생하게 된다.

Negative Sampling
Negative Sampling는 모든 클래스에 대해 계산하는 대신, 일부 negative만 샘플링하여 계산하자는 아이디어이다. 대부분의 클래스들은 해당 input x에 대해 이미 0에 가까운 값을 갖기 때문에 굳이 모든 파라미터를 업데이트할 필요가 없다.

SimCLR( A Simple Framework for Contrastive Learning of Visual Representations, 2020)
Self-Supervised Contrastive Learning framework인 SimCLR은 같은 이미지에서 생긴 두 개의 Augmentation은 서로 가까이, 다른 이미지에서 생성된 Augmentation은 멀리 임베딩되도록 학습한다.
1. Data Augmentation
- 입력 이미지에 두 번 augmentation 적용
- Random crop, color jitter, blur 등
2. Base Encoder
- CNN(ResNet)으로 각각 feature vector h로 변환
- h = f(x)
3. Projection Head
- 작은 MLP로 임베딩 z = g(h)로 매핑
- contrastive loss는 z에 적용
4. NT-Xent Loss (Normalized Temperature-scaled Cross Entropy Loss)
- Batch size = N 일 때, 2(N - 1)개는 negative, 같은 이미지의 두 view는 positive로 사용
- contrastive loss
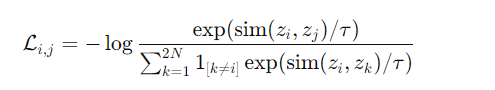
- z_i, z_j: 같은 이미지의 두 augment된 임베딩
- τ: temperature scalar
- sim(a, b): cosine similarity
- 모든 sample이 anchor 역할을 하며 2N개의 sample에 대해 loss 계산


Noise Contrastive Estimator (NCE)
NCE (Noise Contrastive Estimation)는 확률 모델의 정규화 상수(분모)를 계산하지 않고도 파라미터를 학습할 수 있게 해주는 확률분포 추정 기법이다. 특히 softmax의 계산 복잡도가 높은 상황에서 효과적으로 사용된다.
NCE는 원래 Word2vec에서 먼저 적용된 학습 방식이다. 기존에 Word2vec은 중심 단어를 보고 주변 단어를 예측하던 방식이었다. NCE는 이 방식을 두 단어가 같은 문맥에서 왔는지, 아니면 랜덤 쌍인지를 구별하는 binary classification 문제로 바꾸었다.(True pair: 중심 단어, 주변 맥락, Fake pair: 임의 단어 2개) 학습이 잘 되면 모델은 단어 벡터를 학습하게 된다. 결국 단어 벡터를 분류 문제로 학습한다는 점이 NCE의 포인트이다.

먼저, 주어진 샘플 {x .. }은 실제 데이터 분포 p_m(x)에서 생성된 것이라고 가정하고, 현재 목표는 이 분포 p_m(x)를 근사하는 것이다. 이를 위해, 별도로 정의된 가짜 분포 p_n에서 N개의 샘플 {y ...}을 샘플링한다.
학습은 모델이 입력 샘플이 실제 데이터에서 온 것인지 또는 가짜(노이즈) 분포에서 온 것인지를 구별하도록 훈련하는 방식이다. 즉, 이 과정을 binary classification 문제로 바꾸고 logistic regression로 해결한다.

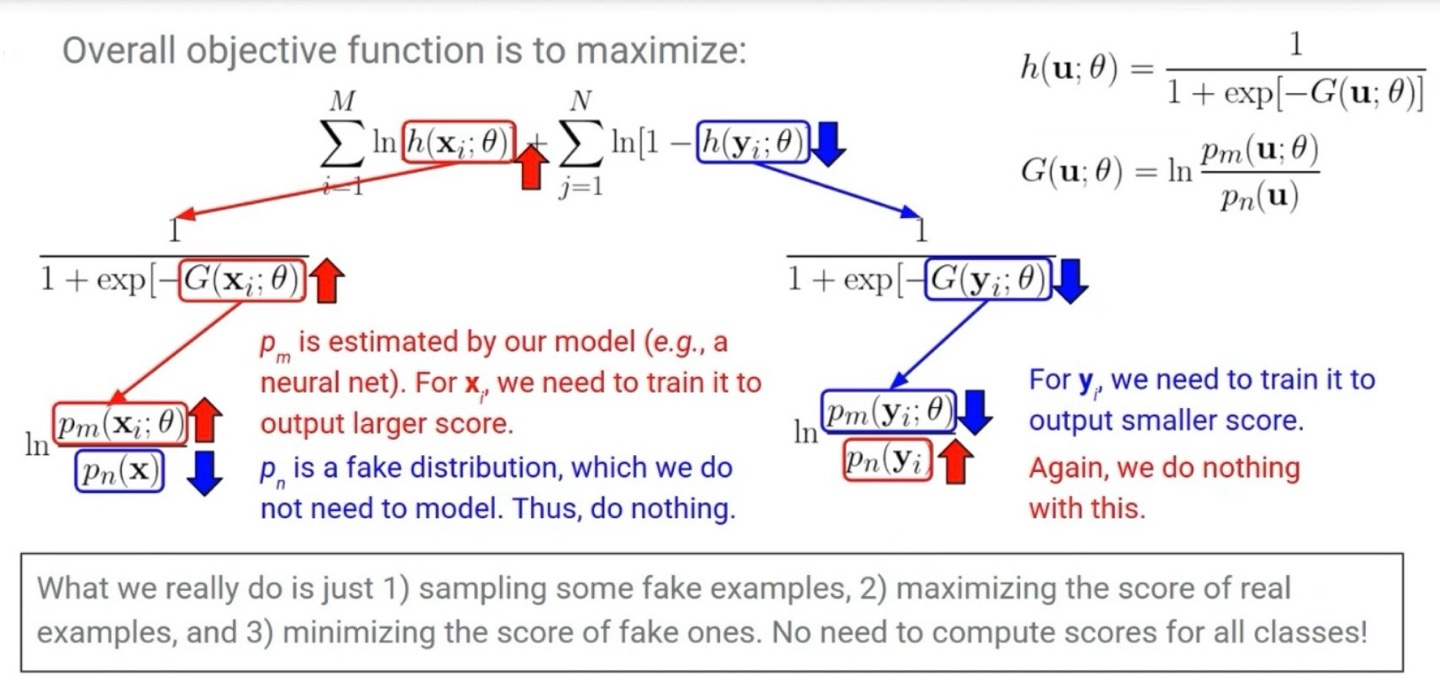
1. 전체 목적 함수

2. G(u; θ) 정의
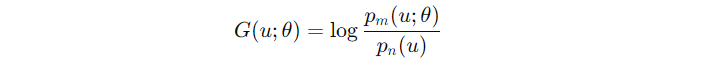
- 모델은 이 비율을 직접 예측하도록 학습된다.
- 단, p_n은 고정된 분포이므로 학습 대상이 아니다.
실제 샘플이 입력되었을 경우 G(x)가 커지도록 학습한다. 즉, 모델이 실제 데이터를 잘 분류하도록 유도한다.
→ G(x_i) 커지면 h(x_i) , loss 감소
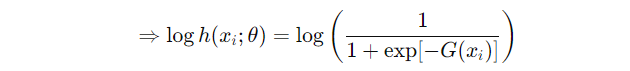
가짜 샘플이 입력되었을 경우 G(y)가 작아지도록 학습한다. 즉, p_m(y)가 작아지도록 학습한다.
→ G(y_i) 커지면 h(y_i) , loss 감소
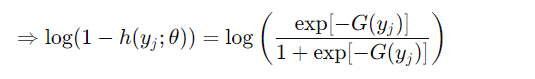
정리하면 가짜 샘플 y를 가짜 분포인 p_n에서 샘플링하고, 모델은 실제 샘플 x의 score G(x)를 최대한 크게 만들고, 가짜 샘플 y의 score G(y)를 최대한 작게 만든다. 따라서 모든 클래스의 score를 계산할 필요가 없게 된다. (Softmax와의 가장 큰 차이점)