[밑바닥부터 시작하는 딥러닝1: Chapter 8] 딥러닝
본 포스팅은 밑바닥부터 시작하는 딥러닝1을 토대로 공부한 내용을 정리하기 위한 포스팅입니다.
해당 도서에 나오는 Source Code 및 자료는 GitHub를 참조하여 진행하였습니다.
https://github.com/WegraLee/deep-learning-from-scratch
8.1 더 깊게
그동안 공부한 기술들로 심층 신경망을 만들어 MNIST 데이터셋의 손글씨 숫자 인식 정확도를 계산해본다. [그림 8-1]과 같이 구성된 CNN을 구현했다고 하자.
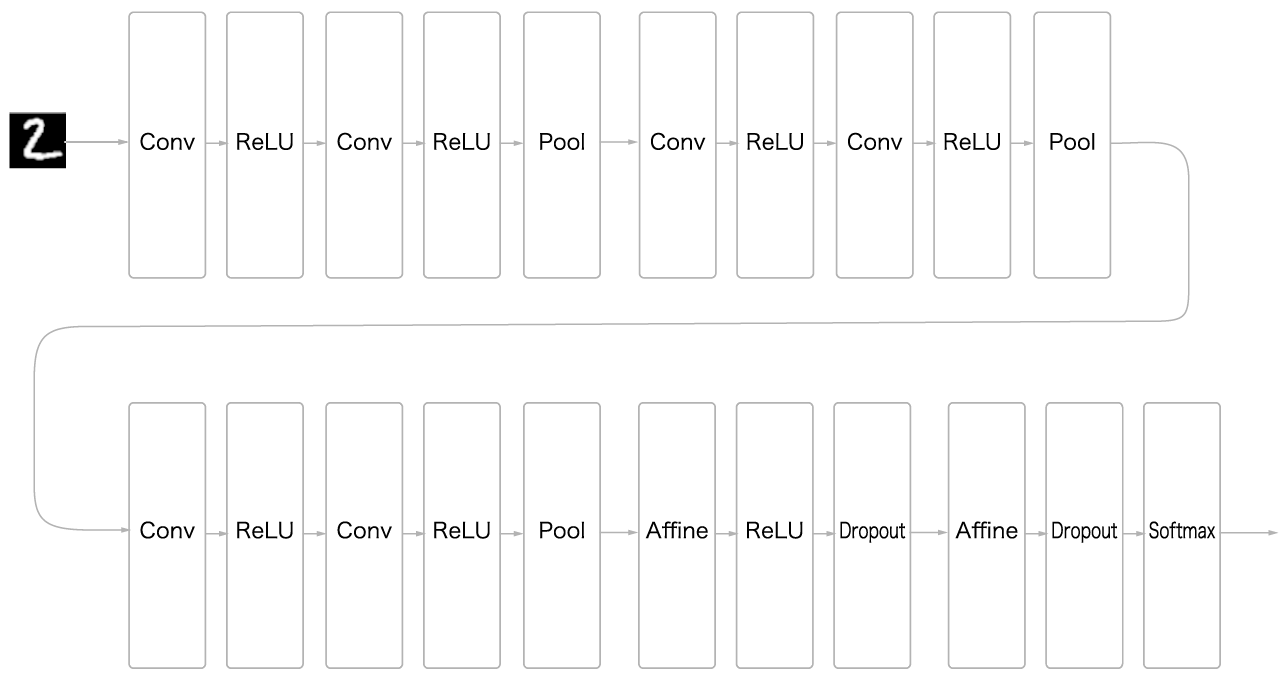
이 신경망의 특징은 다음과 같다.
- 3x3의 작은 필터를 사용한 합성곱 계층
- 활성화 함수는 ReLU
- 완전연결 계층 뒤에 드롭아웃 계층 사용
- Adam을 사용해 최적화
- 가중치 초깃값은 ‘He의 초깃값‘
이 신경망을 학습여 정확도를 구하면 대략 99.38%가 된다. 이 신경망들이 인식하지 못한 이미지들은 [그림 8-2]이다.

이처럼 심층 CNN은 정확도가 높고, 잘못 인식한 이미지들은 인간조차도 인식 오류를 일으키는 이미지이다. 이를 통해 CNN의 잠재력이 크다는 걸 깨달을 수 있다.

[그림 8-3]은 MNIST 데이터셋에 대한 각 기법들을 정확도를 기준으로 매긴 순위이다. 상위권은 대부분 CNN을 기초로 한 기법들이며, 앙상블 학습, 학습률 감소, 데이터 확장 등이 정확도를 향상시키고 있다.
그중에서 데이터 확장(data augmentation)은 입력 이미지(훈련 이미지)를 ‘인위적’으로 확장하는 것이다. [그림 8-4]와 같이 입력 이미지를 회전하거나 세로로 이동하는 등 미세한 변화를 주어 이미지의 개수를 늘리는 것이다. 이는 데이터가 몇 개 없을 때 효과적인 수단이다. 이러한 변형 외에도 이미지 일부를 잘라내는 crop이나 좌우를 뒤집는 flip, 밝기 등의 외형 변화나 확대, 축소 등의 스케일 변화들이 있다. 이처럼 데이터 확장을 동원해 훈련 이미지의 개수를 늘리면 딥러닝의 인식 수준을 크게 개선할 수 있다.
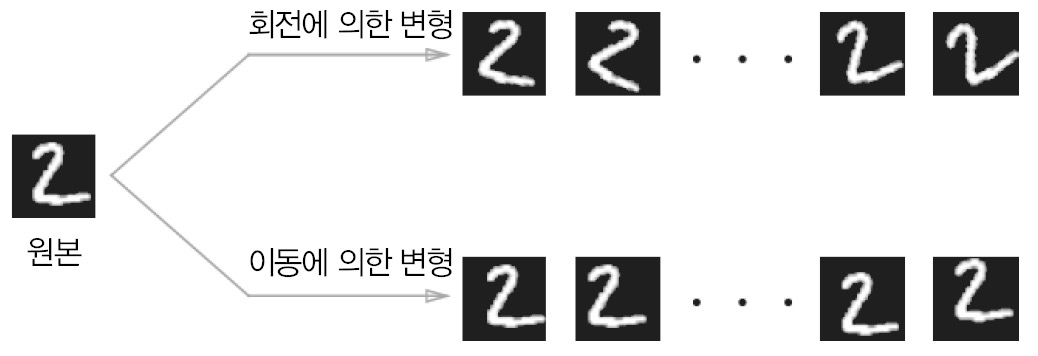
8.1.3 층을 깊게 하는 이유
딥러닝의 층을 깊게 하게 되면, 신경망의 매개변수 수가 줄어들게 된다. 덕분에 학습 데이터의 양을 줄일 수 있어 학습을 고속으로 수행 가능하다. 그리고 신경망을 깊게 하면 학습해야 할 문제를 계층적으로 분해할 수 있다. 각 층이 학습해야 할 문제를 더 단순한 문제로 대체할 수 있는 것이다. 예를 들어 처음 층은 edge 학습으로 시작해서 마지막에는 개의 패턴을 인식하도록 하는 것이 가능하다.
또, 층을 깊게 하면 정보를 계층적으로 전달할 수 있다. 예를 들어 edge를 추출한 층의 다음 층은 edge 정보를 쓸 수 있고, 더 고도의 패턴을 층을 거치며 효과적으로 학습할 수 있는 것이다.
8.2 딥러닝의 초기 역사
딥러닝은 이미지 인식 기술을 겨루는 대회인 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)의 2012년 대회에서 AlexNet이 압도적인 성적으로 우승하면서 주목받게 되었다.

ILSVRC 대회에서는 시험 항목이 몇 가지 있는데, 그 중 분류(classification)가 있다. 분류 부문에서는 1,000개의 클래스를 제대로 분류하는지를 보는데, 분류부분의 top-5 error를 막대 그래프로 나타내면 [그림 8-8]과 같다. top-5 error란 확률이 가장 높다고 생각하는 후보 클래스 5개 안에 정답이 포함되지 않은, 즉 5개 모두가 틀린 비율을 말한다.
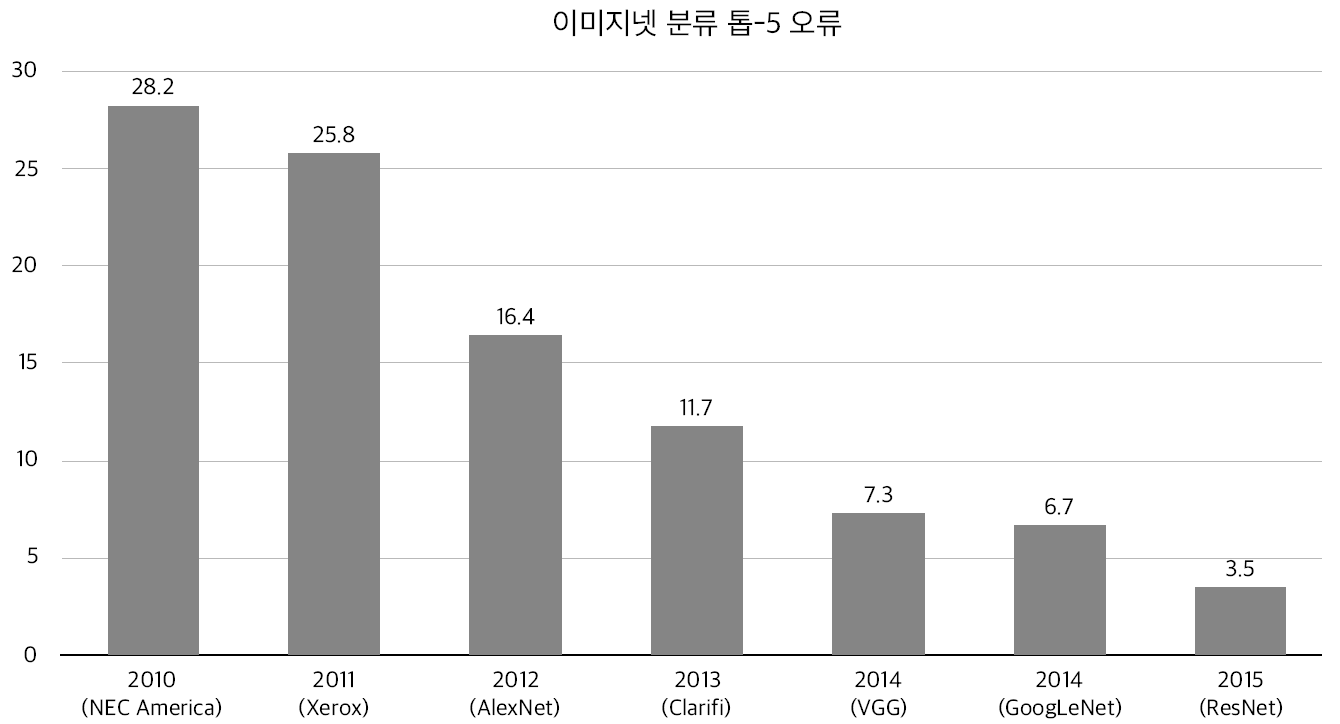
2012년의 AlexNet이 오류율을 크게 낮췄고, 유명한 신경망인 VGG, GoogLeNet, ResNet 모두 매년마다 오류를 줄였다.
8.2.2 VGG
VGG는 합성곱 계층과 풀링 계층으로 구성되는 ‘기본적’인 CNN이다. 다만, [그림 8-9]와 같이 비중 있는 층(합성곱 계층, 완전연결 계층)을 모두 16~19층으로 심화한 게 특징이다.
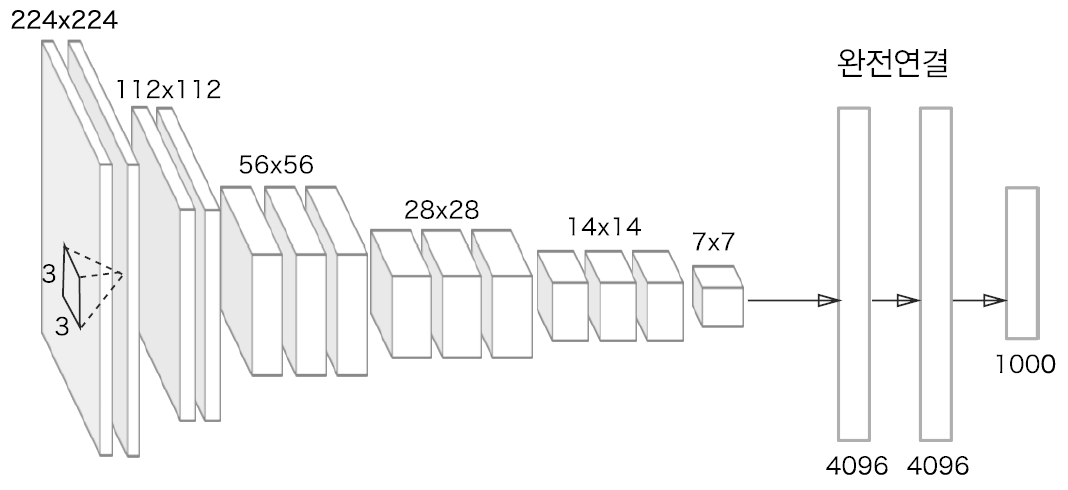
VGG에서 주목할 점은 3x3의 작은 필터를 사용한 합성곱 계층을 연속으로 거친다는 것이다. 그림에서 보듯 합성곱 계층을 2~4회 연속으로 풀링 계층을 두어 크기를 절반으로 줄이는 처리를 반복한다. 그리고 마지막에는 완전연결 계층을 통과시켜 결과를 출력한다.
8.2.3 GoogLeNet
GoogLeNet의 구성은 [그림 8-10]과 같다.
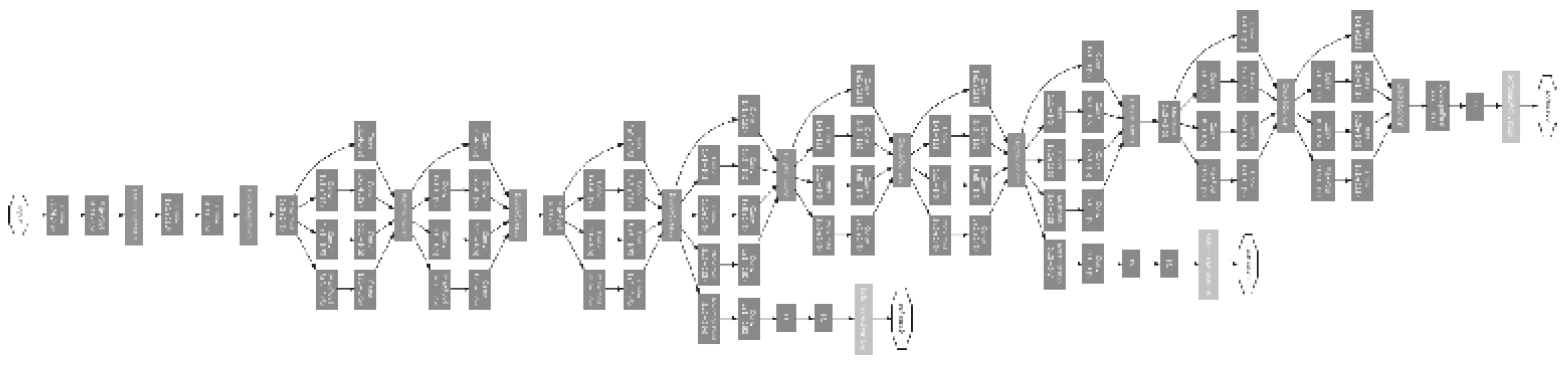
GoogLeNet은 세로 방향 깊이뿐 아니라 가로 방향도 깊다는 점이 특징이다. GoogLeNet에는 가로 방향에 ‘폭’이 있다. 이를 인셉션 구조라 하며, 그 기반 구조는 [그림 8-11]과 같다.
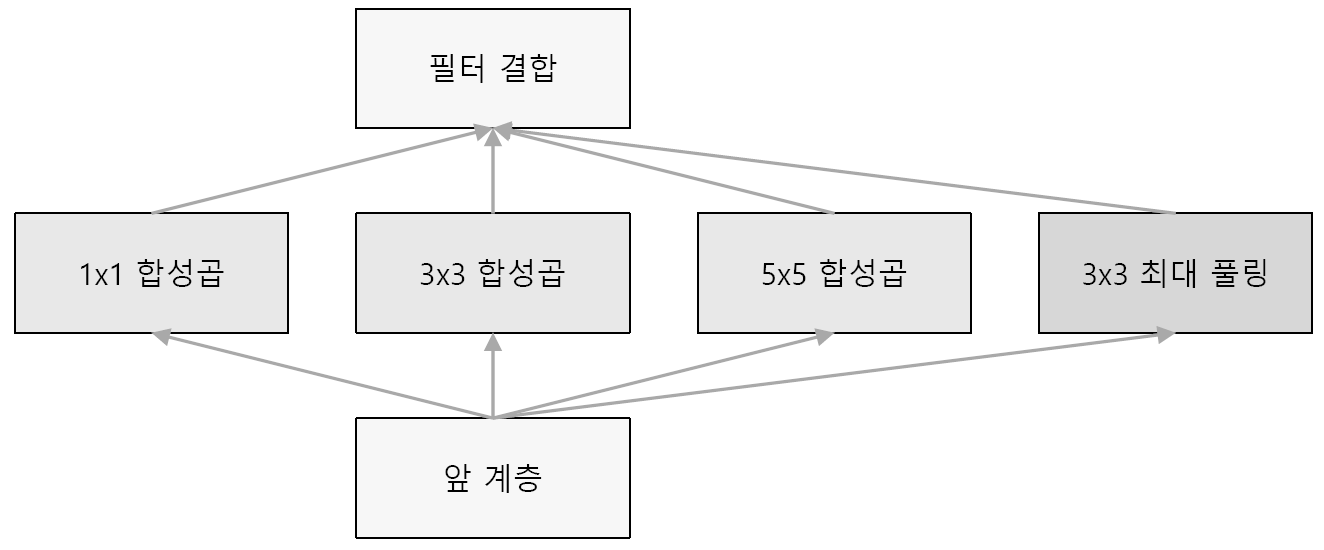
인셉션 구조는 [그림 8-11]과 같이 크기가 다른 필터(와 풀링)를 여러 개 적용하여 그 결과를 결합한다. 이 인셉션 구조를 하나의 빌딩 블록으로 사용하는 것이 GoogLeNet의 특징이다. 또, 1x1 크기의 필터를 사용한 합성곱 계층을 많은 곳에서 사용한다. 이는 채널 쪽으로 크기를 줄이며, 매개변수 제거와 고속 처리에 기여한다.
8.2.4 ResNet
ResNet(Residual Network)은 마이크로소프트의 팀이 개발한 네트워크이다. ResNet에서는 딥러닝의 지나친 층의 깊이로 인한 부작용을 해결하기 위해서 스킵 연결(skip connection)을 도입한다. 이 구조가 층의 깊이에 비례해 성능을 향상시킬 수 있게 한 핵심이다.
스킵 연결이란 [그림 8-12]와 같이 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조를 말한다.

[그림 8-12]에서는 입력 x를 연속한 두 합성곱 계층을 건너뛰어 출력에 바로 연결한다. 이 스킵 연결은 층이 깊어져도 학습을 효율적으로 할 수 있도록 해주는데, 이는 역전파 때 스킵 연결이 신호 감쇠를 막아주기 때문이다. 즉, 층을 깊게 할수록 기울기가 작아지는 소실 문제를 스킵 연결이 줄여주는 것이다.
ResNet은 먼저 설명한 VGG 신경망을 기반으로 스킵 연결을 도입하여 층을 깊게 했다. 그 결과는 [그림 8-13]처럼 된다.

[그림 8-13]과 같이 ResNet은 합성곱 계층을 2개 층마다 건너뛰면서 층을 깊게 한다. 실험을 했을때 150층 이상으로 해도 정확도가 오른다고 한다.
8.3 딥러닝 고속화
딥러닝은 대량의 연산을 수행해야 한다. 과거에는 CPU가 계산을 담당했으나, 현재의 딥러닝 프레임워크들은 GPU(Graphics Processing Unit)를 활용해 대량의 연산을 고속으로 처리한다.

[그림 8-14]는 AlexNet에서는 합성곱 계층에서 오랜 시간을 소요함을 알 수 있다. 이처럼 합성곱 계층에서 이뤄지는 연산을 어떻게 고속으로 효율적으로 하느냐가 딥러닝에 중요하다.
GPU는 병렬 수치 연산을 고속으로 처리할 수 있는데, 딥러닝에서는 대량의 단일 곱셈-누산(또는 큰 행렬의 곱)을 수행해야 하므로 딥러닝 연산에서 GPU를 이용하면 CPU를 쓸 때보다 더 빠르게 결과를 얻을 수 있는 것이다. AlexNet의 학습 시간을 CPU와 GPU에서 비교한 결과는 [그림 8-15]와 같다.
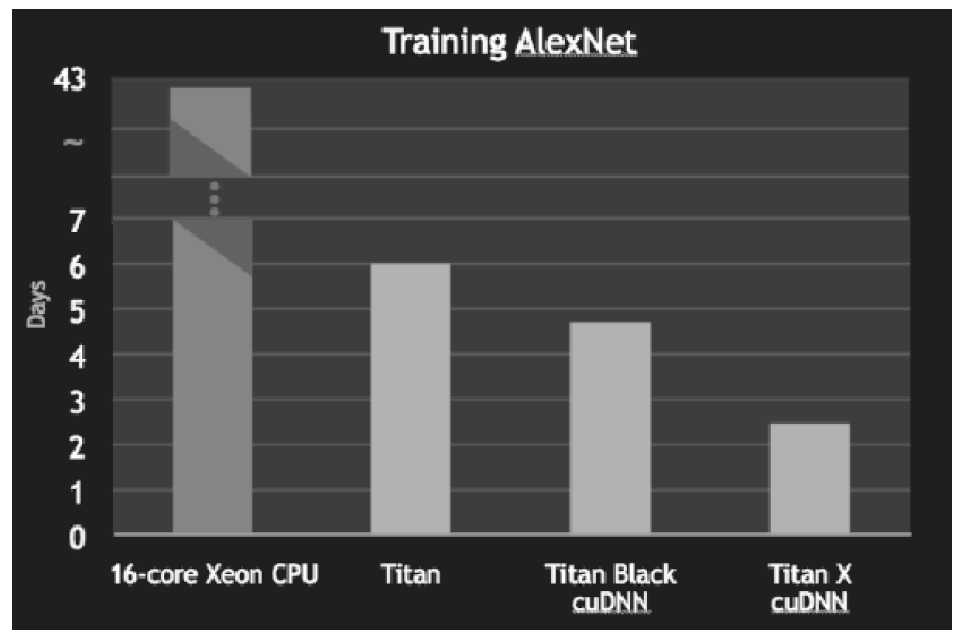
그림과 같이 CPU에서는 40여 일이나 걸리지만 GPU로는 6일까지 단축되었다. 또, cuDNN이라는 딥러닝에 최적화된 라이브러리를 이용하면 더욱 빨라진다.
8.4 딥러닝의 활용
딥러닝은 이미지, 음성, 자연어 등 수많은 분야에서 사용 가능하다. 이번에는 딥러닝이 할 수 있는 것을 컴퓨터 비전 분야를 중심으로 알아보도록 한다.
8.4.1 사물 검출
사물 검출은 [그림 8-16]과 같이 이미지 속에 담긴 사물의 위치와 종류(클래스)를 알아내는 기술이다.

이 그림에서 보듯 사물 검출은 사물 인식보다 어려운 문제이다. 사물 검출은 이미지 어딘가에 있을 사물의 위치를 알아내야 한다. CNN을 이용하여 사물 검출을 수행하는 방식은 몇 가지가 있는데, 그중에서도 R-CNN(Regions with Convolutional Neural Network)이 유명하다. [그림 8-17]은 R-CNN의 처리 흐름이다.

R-CNN 처리 흐름에서 주목할 곳은 ‘후보 영역 추출’과 ‘CNN 특징 계산’이다. 먼저 사물이 위치한 영역을 찾아내고, 추출한 각 영역에 CNN을 적용하여 클래스를 분류하는 것이다. 여기서 이미지를 사각형으로 변형하거나 분류할 때 서포트 벡터 머신(SVM)을 사용하는 등 실제 처리 흐름은 복잡하지만, 큰 틀에서는 이 두 가지 처리로 구성된다.
후보 영역 추출에는 컴퓨터 비전 분야에서 발전해온 다양한 기법과 Selective Search 기법을 사용한다. 심지어는 후보 영역 추출까지도 CNN으로 처리하는 Faster R-CNN 기법도 있다. Fater R-CNN은 모든 일을 하나의 CNN에서 처리하므로 속도가 아주 빠르다.
8.4.2 분할
분할(segmentation)이란 이미지를 픽셀 수준에서 분류하는 문제이다. [그림 8-18]와 같이 픽셀 단위로 객체마다 채색된 지도(supervised) 데이터를 사용해 학습한다. 그리고 추론할 때 입력 이미지의 모든 픽셀을 분류한다.

FCN(Fully Convolutional Network)는 단 한 번의 forward 처리로 모든 픽셀의 클래스를 분류해주는 기법이다.(그림 8-19}
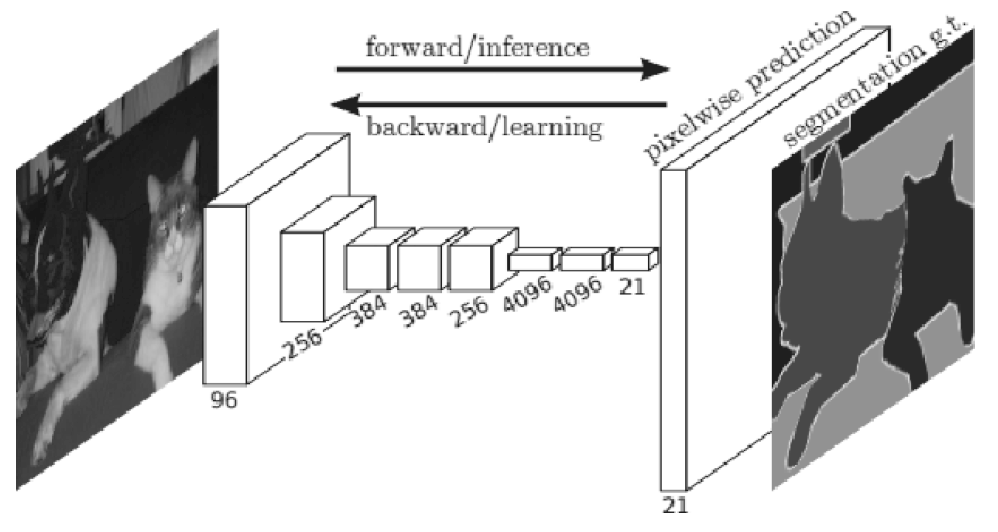
Fully Convolutional Network를 직역하면 ‘합성곱 계층만으로 구성된 네트워크’이다.
일반적인 CNN이 완전연결 계층을 이용하는 반면, FCN은 이 완전연결 계층을 ‘같은 기능을 하는 합성곱 계층’으로 바꾼다. 이 덕에 사물 인식에서 사용한 신경망의 완전연결 계층에서는 중간 데이터의 공간 볼륨(다차원 형태)을 1차원으로 변환하여 한 줄로 늘어선 노드들이 처리했으나, FCN에서는 공간 볼륨을 유지한 채 마지막 출력까지 처리할 수 있다.
FCN은 [그림 8-19]에서 보듯 마지막에 공간 크기를 확대하는 처리도 있다. 이 확대 처리로 인해 줄어든 중간 데이터를 입력 이미지와 같은 크기까지 단번에 확대할 수 있다. FCN의 마지막에 수행하는 확대는 이중 선형 보간(bilinear interpolation)에 의한 선형 확대이다. FCN에서는 이 선형 확대를 역합성곱(deconvolution) 연산으로 구현해내고 있다.
8.4.3 사진 캡션 생성
[그림 8-20]는 사진을 주면, 그 사진을 설명하는 글을 자동으로 생성하는 연구이다. 컴퓨터 비전과 자연어를 융합한 결과물이다.

ㄷ비러닝으로 사진 캡션을 생성하는 방법으로는 NIC(Neural Image Caption) 모델이 대표적이다. NIC는 [그림 8-21]과 같이 심층 CNN과 자연어를 다루는 순환 신경망(Recurrent Neural Network, RNN)으로 구성된다. RNN은 순환적 관계를 갖는 신경망으로 자연어나 시계열 데이터 등의 연속된 데이터를 다룰 때 많이 활용한다.
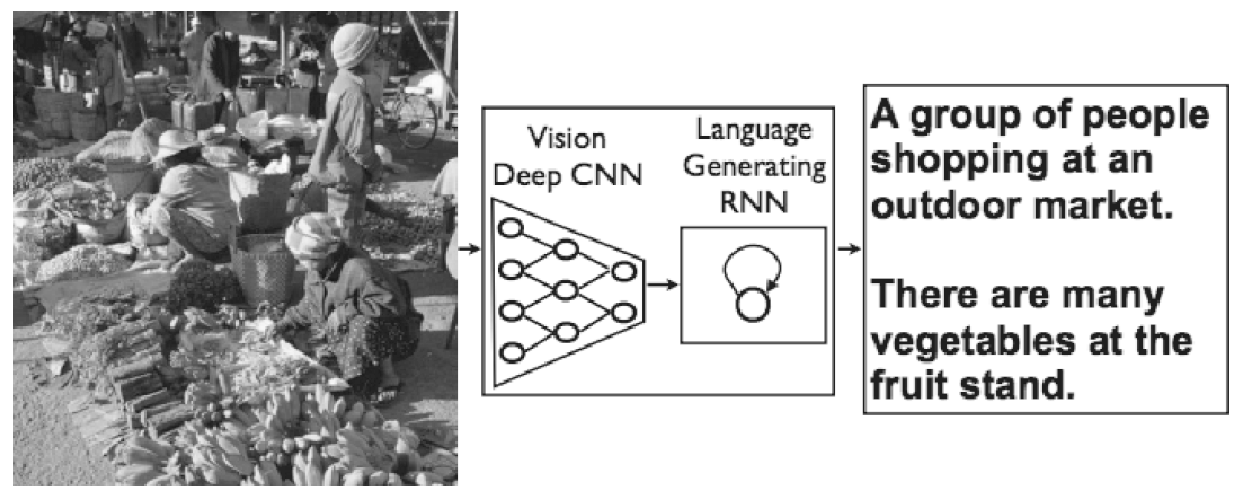
NIC는 CNN으로 사진에서 특징을 추출하고, 그 특징을 RNN에 넘긴다. RNN은 CNN이 추출한 특징을 초깃값으로 해서 텍스트를 ‘순환적’으로 생성한다. 기본적으로 NIC는 2개의 신경망(CNN과 RNN)을 조합한 간단한 구성이다. 사진이나 자연어와 같은 여러 종류의 정보를 조합하고 처리하는 것을 멀티모달 처리(multimodal processing)라고 한다.
8.5 딥러닝의 미래
8.5.1 이미지 스타일(화풍) 변환
[그림 8-22]은 두 이미지를 입력해서 새로운 그림을 생성하는 연구이다. 하나는 ‘콘텐츠 이미지’, 다른 하나는 ‘스타일 이미지’라 부르는데, 이 둘을 조합해 새로운 그림을 그린 것이다. 이 기법을 담은 논문은 [A Neural Algorithm of Artistic Style]이다.

이 기술은 네트워크의 중간 데이터가 콘텐츠 이미지의 중간 데이터와 비슷해지도록 학습한다. 이렇게 하면 입력 이미지를 콘텐츠 이미지의 형태로 흉내 낼 수 있다. 또, 스타일 이미지의 화풍을 흡수하기 위해 ‘스타일 행렬’이라는 개념을 도입한다. 그 스타일 행렬의 오차를 줄이도록 학습하여 입력 이미지를 콘텐츠 이미지와 비슷해지게 만들 수 있는 것이다.
8.5.2 이미지 생성
앞의 이미지 스타일 변환 예는 새로운 그림을 생성하려면 이미 두 장을 입력해야 했다. 이에 반해 아무런 입력 이미지 없이도 새로운 이미지를 그려내는 연구도 존재한다. [그림 8-24]의 이미지는 DCGAN(Deep Convolutional Generative Adversarial Network) 기법으로 생성한 침실 이미지들이다.

[그림 8-23]의 이미지들은 모두 DCGAN을 사용해 새롭게 생성한 이미지이다. 즉, 학습 데이터에는 존재하지 않는 이미지이며, 처음부터 새로 생성한 이미지이다.
DCGAN 기술의 핵심은 생성자(Generator)와 식별자(Discriminator)로 불리는 2개의 신경망을 이용해 생성자가 진짜와 똑같은 이미지를 생성하면, 식별자는 그것이 진짜인지(생성자가 생성한 이미지인지, 아니면 실제로 촬영된 이미지인지)를 판정하도록 하는것이다. 그렇게 해서 둘을 겨루도록 학습시켜, 생성자는 더 정교한 가짜 이미지 생성 기술을 학습하고 식별자는 더 정확하게 간파할 수 있도록 학습되는 것이다. 이렇게 두 신경망의 성능을 향상시킨다는 개념이 GAN(Generative Adversarial Network) 기술의 특징이다.
8.5.3 자율 주행
SegNet이라는 CNN 기반 신경망은 [그림 8-25]와 같이 주변 환경을 정확하게 인식해낸다. 입력 이미지를 분할(픽셀 수준에서 판정)하고 있다. 결과를 보면 도로와 건물, 보도와 나무, 차량과 오토바이 등을 어느 정도 정확히 판별하는 것을 볼 수 있다.

8.5.4 Depp Q-Network(강화학습)
강화학습(reinforcement learning)은 에이전트라는 것이 환경에 맞게 행동을 선택하고, 그 행동에 의해서 환경이 변한다는 기본적인 틀을 가지고 있다. 환경이 변화하면 에이전트는 어떠한 보상을 얻는다. 강화 학습의 목적은 이러한 보상을 더 나은 쪽으로 받도록 에이전트의 행동 지침을 바로잡는 것이다.(그림 8-25)
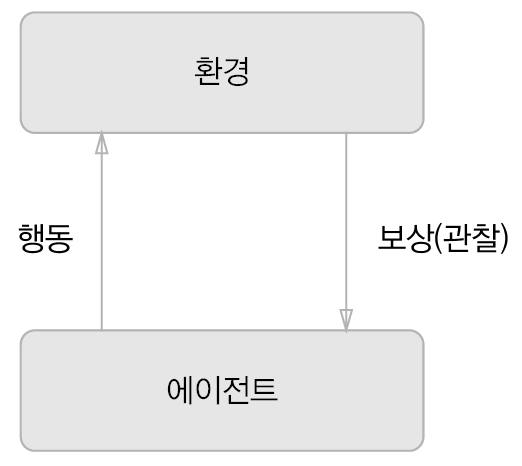
[그림 8-25]은 강화학습의 기본 틀이다. 여기에서 주의점은 보상은 정해진 것이 아니라 ‘예상 보상’이라는 점이다. 딥러닝을 사용한 강화학습 중 Depp Q-Network(DQN)라는 방법이 있다. 이는 Q학습이라는 강화학습 알고리즘을 기초로 한다. Q학습에서는 최적 행동 가치 함수로 최적인 행동을 정한다. 이 함수를 딥러닝(CNN)으로 비슷하게 흉내 내어 사용하는 것이 DQN이다.
DQN 연구 중에는 비디오 게임을 자율 학습시켜 사람을 뛰어넘는 수준의 조작을 실현한 사례가 있다. [그림 8-26]과 같이 DQN에서 사용하는 CNN은 게임 영상 프레임(4개의 연속한 프레임)을 입력하여 최종적으로는 게임을 제어하는 움직임에 대하여 각 동작의 ‘가치’를 출력한다.
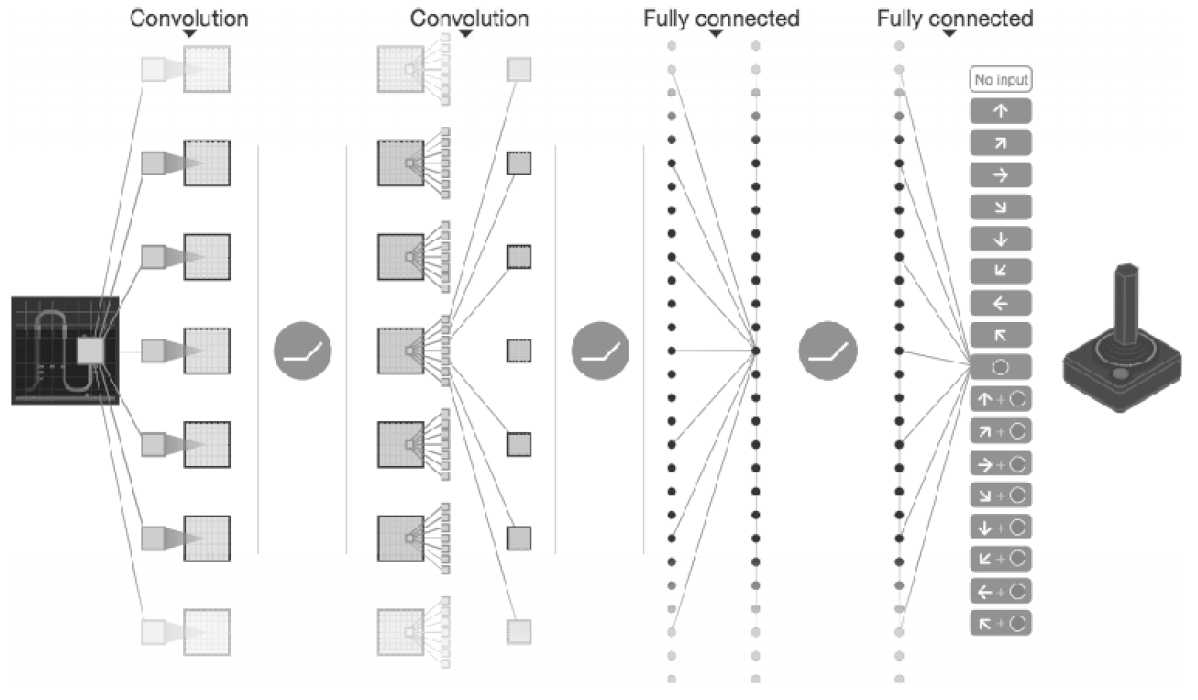
DQN에서는 [그림 8-26]과 같이 입력 데이터는 비디오 게임의 영상이다. 이는 DQN의 주목할 점으로, DQN은 응용 가능성이 높아 게임마다 설정을 바꿀 필요없다는 것을 시사한다. 실제 DQN은 구성을 변경하지 않고도 팩맨과 아타리같은 많은 게임을 학습할 수 있으며, 수많은 게임에서 사람보다 뛰어난 성적을 거두고 있다. 알파고(AlphaGo) 역시 딥러닝과 강화학습을 이용한 인공지능이다.